一段代码在Spark中的执行过程
假如我们的Spark的资源调度是基于Yarn的, 并且有这样一段代码, 我们来分析一下它从提交开始到返回结果的执行过程
|
|
提交任务
这里的提交一般有两种方式, 一种是client模式, 一种是cluster模式
- client
这种模式的意思是将提交作业的机器作为Driver来管理任务
- cluster
这种模式会在Yarn集群中选择一个机器来作为Driver
在生产环境下我们一般都会使用Cluster模式来提交任务
分解任务
在Driver上根据我们的代码逻辑, 将作业进行Stage切分, 然后将任务派发到Executor上
生成逻辑计划
首先使用Altur4来将我们的代码转换成逻辑树, 如果我们写的代码有问题, 比如少写了一个括号, 少写了一个关键字等等可能会造成无法构建逻辑树时, 会在这里抛出错误.
假如我们在查询字段中少写了一个逗号, 造成了as这样的语义, 也是在这样生成的

得到Unresolved Logical Plan
然后使用Catalyst进行优化
-
结合Schema信息, 来确定计划中的表名, 字段名, 字段类型是否与实际数据一致 如果我们查询一个不存在的字段, 或者字段类型转换错误等错误会在这里抛出
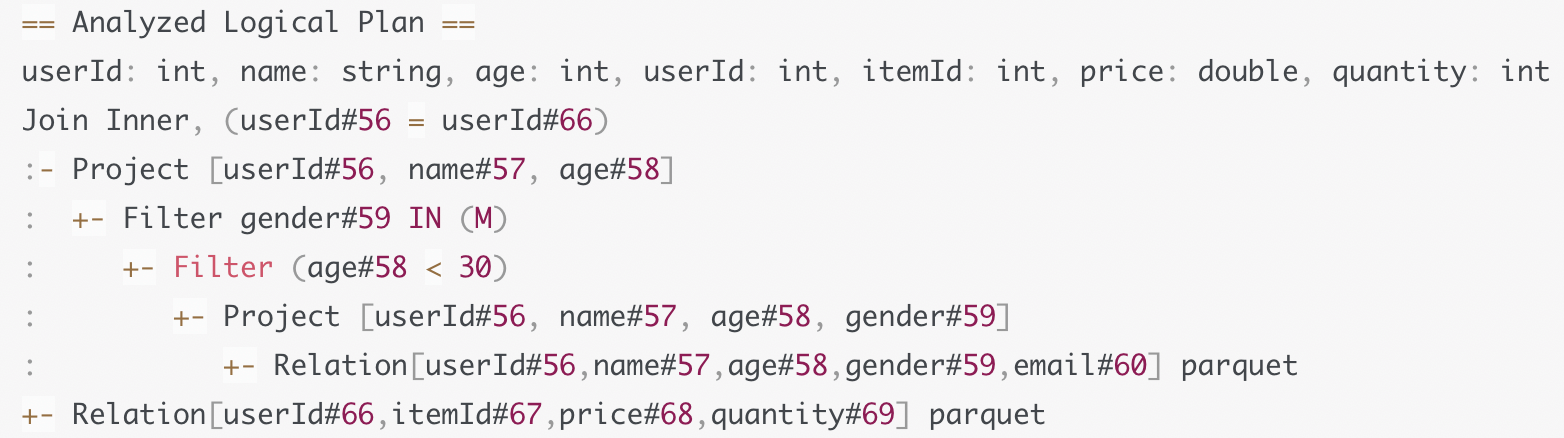
得到Analyzed Logical Plan
-
根据既定规则进行优化
- 列剪裁
- 谓词下推
- 常量替换
我们可能仅仅需要表中的几个字段, 对于列式存储的数据, 我们可以只查询这几列, 从而减少数据扫描量, 降低IO, 提升效率
谓词下推指的是可以将过滤条件下推到可以下推的最下一层, 比如这里的条件过滤, 可以在扫描文件时一起进行过滤, 从而减少源文件大小. 但是要注意的是要保证下推之后不能对结果有影响.
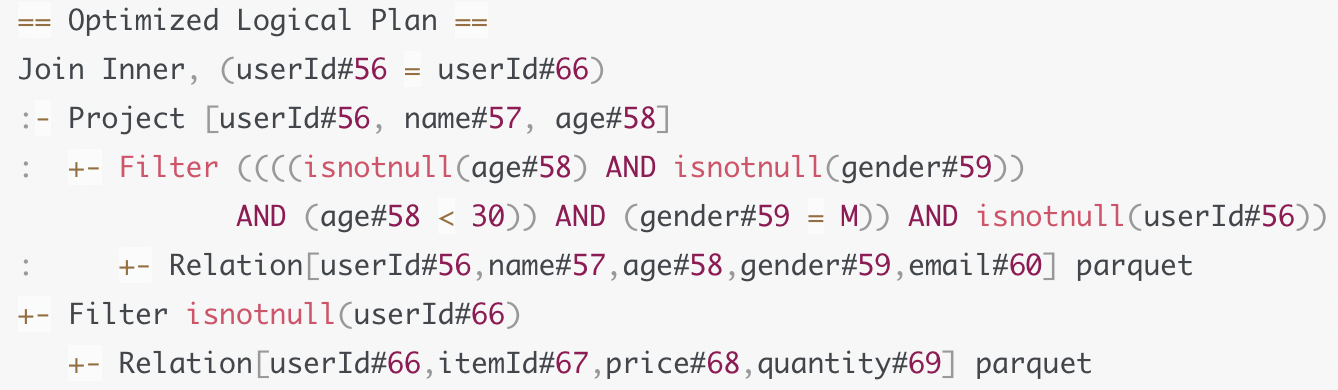
得到Optimized Logical Plan, 至此逻辑计划已经生成, 下面是物理计划
-
生成可以执行的物理计划
逻辑计划生成之后, 只是说明了这个任务需要怎么执行, 但是没有说如何去执行. 上面的Optimized Logical Plan说明了两个表需要进行Inner Join, 但是并没有说明需要shuffle还是broadcast, 需要SMJ还是HJ或者NLJ等等.
所以首先根据既定的规则, 将逻辑计划转换为可以执行的物理计划, 规则有下面这些
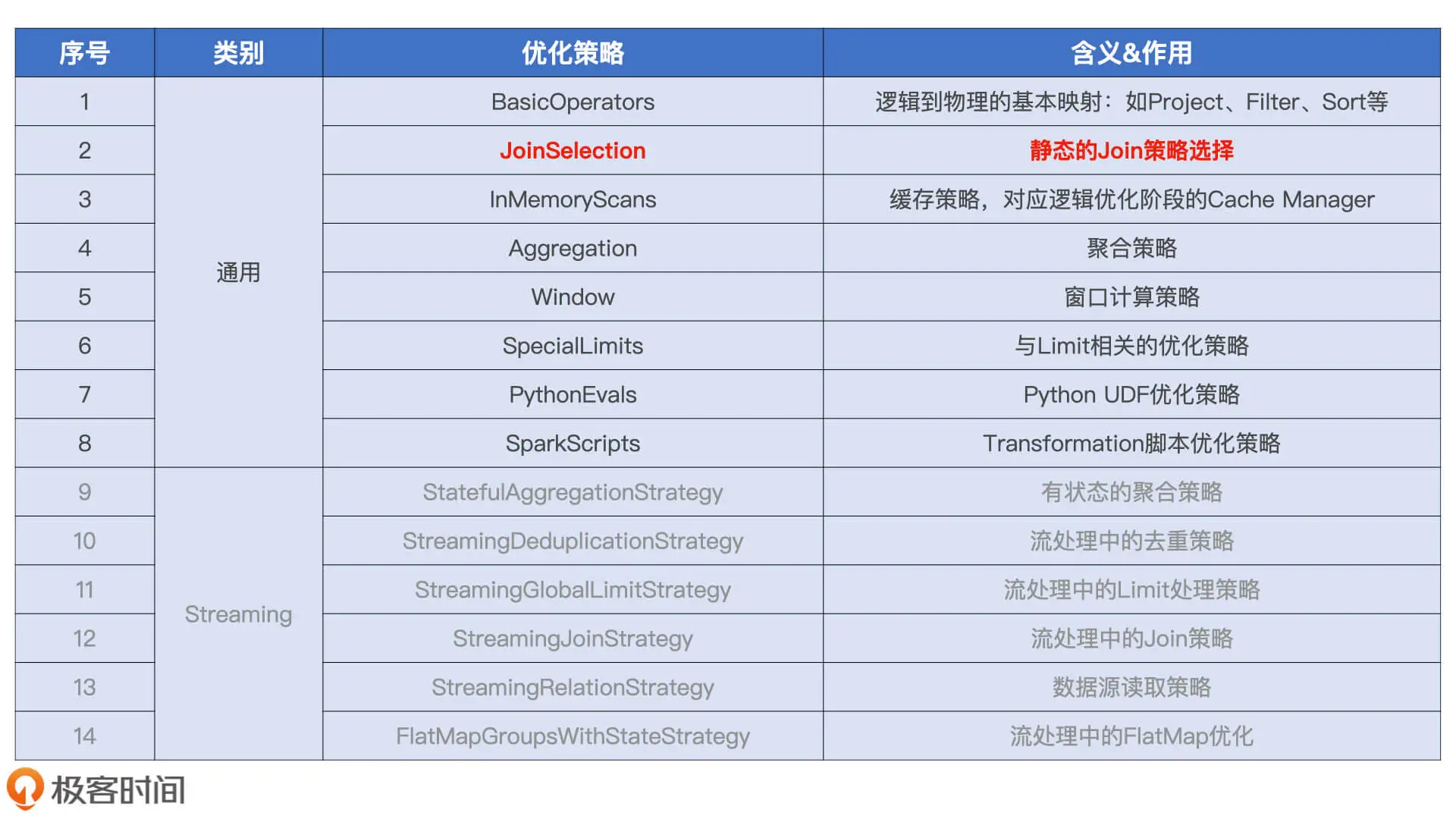
-
再次生成物理计划
上一步将逻辑计划转换成了可以执行的物理计划, 但是有些物理计划要想执行需要满足一系列的先决条件, 这一步就是检查物理计划的执行条件是否全部满足, 如果不满足则进行优化.
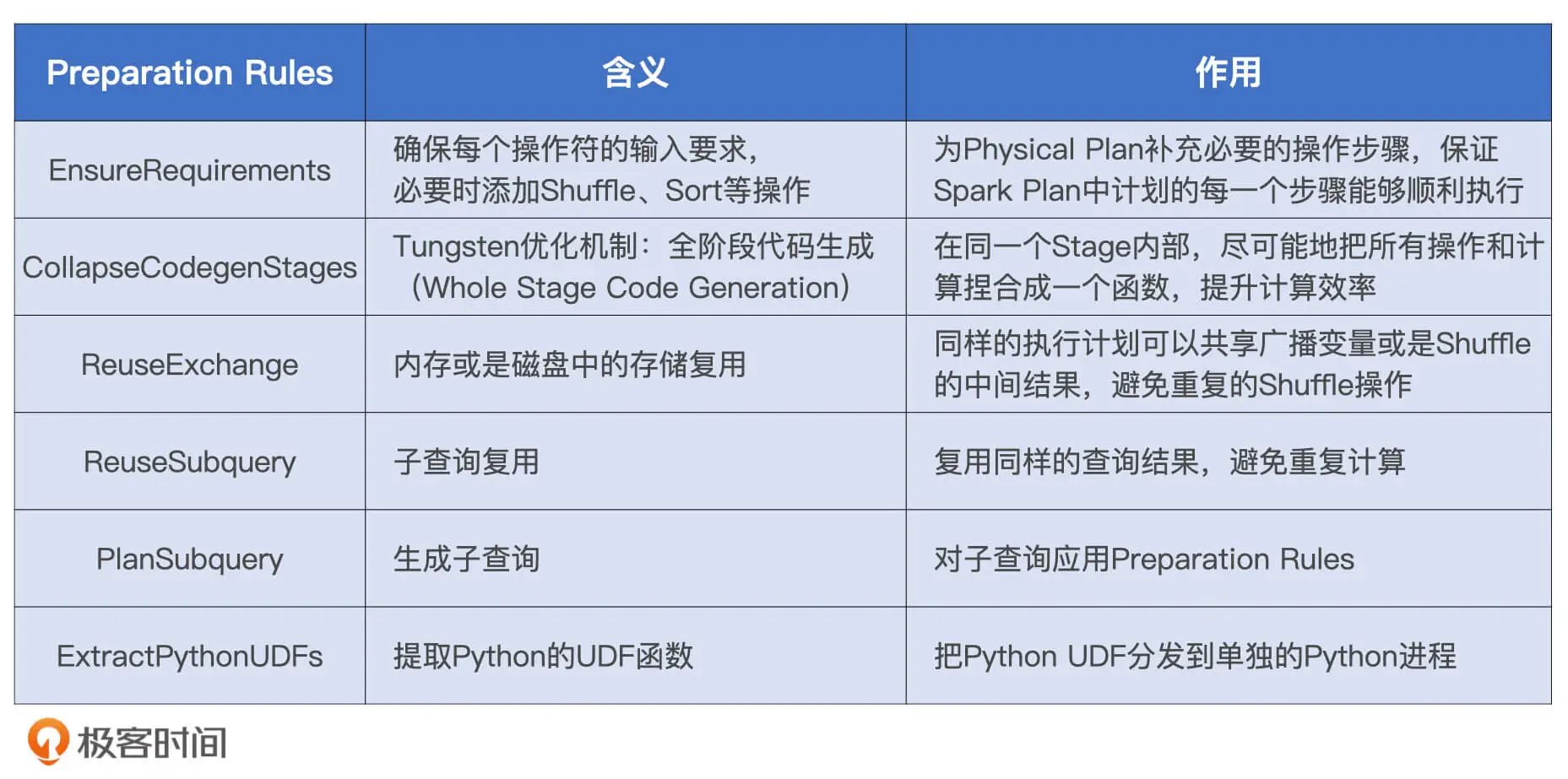
完成之后就生成了最终去执行的物理计划

Tungsten优化
物理计划生成之后可以之间使用, 但是使用Tungsten可以再进行一轮优化. Tungsten主要优化两个方面:
- 数据结构设计
- 全阶段代码生成(Whole Stage Code Generation, WSCG)
数据结构设计主要是使用更加紧凑的二进制来进行数据存储
主要看一下WSCG, 这一步是在Stage中将可以合并的算子进行合并.
还以上面的代码为例, 上面对用户表进行了扫描, 过滤, 然后构建一个投影(Project), 之后再进行Shuffle, 由于Shuffle切分Stage. 所以在第一个Stage就包括这几步:

WSCG可以优化成这样:
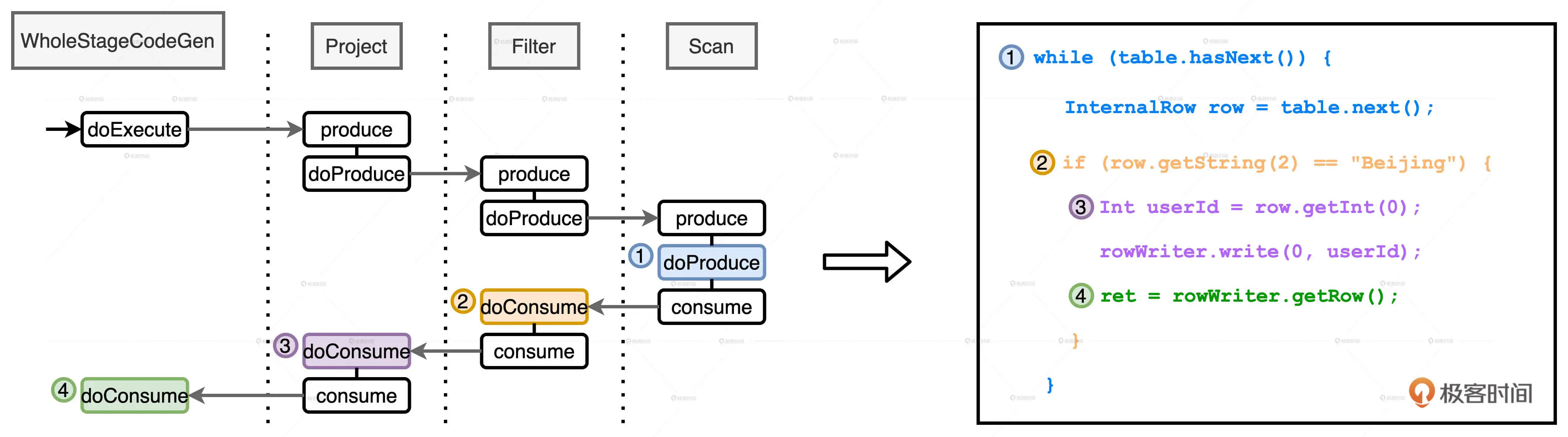
将这三步揉合到一起, 从而只需要扫描和计算一次.
调度和执行
Driver根据配置中的executor数量, 内存, CPU等配置向Yarn申请所需要的Executor. 并将最终的物理计划进行划分, 封装成Task分发到Executor上.
Executor中的线程池拿到Task之后开始运行任务.
Driver会监控Executor的执行情况, 如果遇到可以重试的错误会将这个任务再次分发到其他节点进行执行.