LinkedHashMap继承了HashMap类,实现了Map接口。
他与HashMap的主要区别就是使用链表存储了每个节点的顺序。这样就能保证有序。
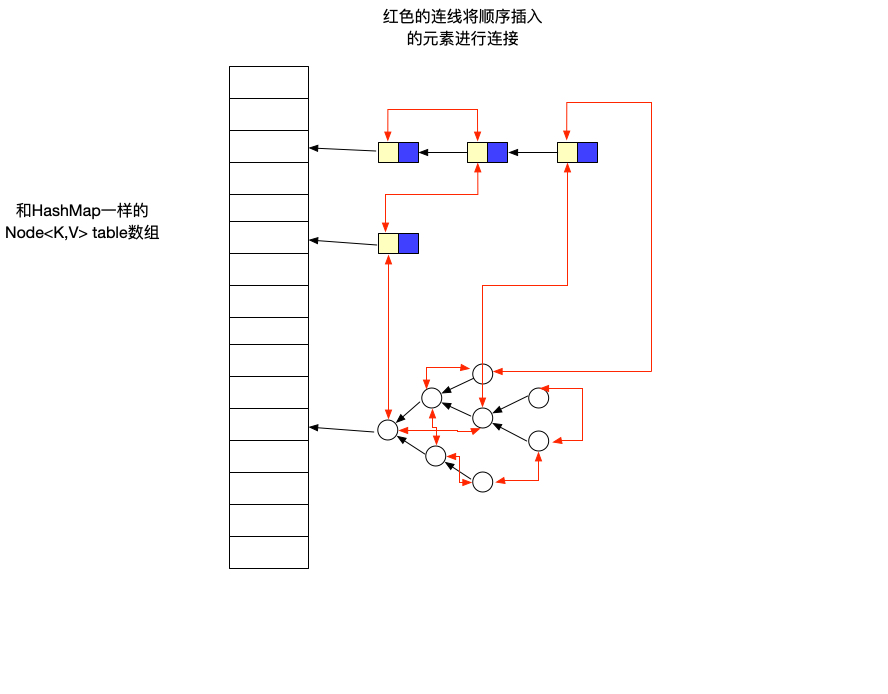
来看一下他的节点情况:
|
|
从这里可以看出他使用了两个变量,before,after存储这个节点的前后顺序。
构造方法
|
|
LinkedHashMap一共有5个构造方法,仔细看一下主要是三个参数:initialCapacity,loadFactor,accessOrder这三个变量。并且他们都调用了父类也就是HashMap的构造方法。
initialCapacity,loadFactor这两个在看HashMap的时候就了解到这是初始容量值与扩容阈值,就不仔细说了,如果想仔细了解这两个字段可以看这一篇HashMap源码学习。
那就主要看一下accessOrder。
|
|
这个字段也给出了注释,如果为true则表示基于访问顺序,如果为false则基于插入顺序。所以我们想要的按照访问顺序取就要设置为false。如果为true则按照访问顺序排序,将访问过的元素放到链表后面。我们用代码看一下实际效果。
|
|
初始化了两个容量,负载系数都一样的LinkedHashMap,第一个设置accessOrder属性为false,第二个设置为true。
然后都执行了相同的代码。先放入元素,然后中间对其中几个元素进行读取。最后在输出查看。
我们可以看到第一个也就是accessOrder属性设置成false的虽然中间获取了元素,但是他的打印顺序还是按照放入顺序的。而第二个中间对两个元素进行了获取,所以他将这两个元素放在了后面,打印顺序是我们放入的顺序再加上访问顺序后最终得到的顺序。
添加元素
调用了父类HashMap的方法。
|
|
先来看afterNodeInsertion方法
|
|
这个方法我就没看明白了,他判断条件三个同时成立才会走,然后第三个条件直接返回了false。这不就永远不执行了,还是说实际调用的是其他实现方法?欢迎大家指教。
获取元素
|
|
现在来看一下之前没说的方法afterNodeAccess
|
|
这里有accessOrder属性的判断,当其为true时才会执行下面的代码,所以只有在构造函数中将这个属性设置成true时这个方法才会走。
这个方法的作用就是将这个节点放到整个链表的最后。如果这个节点有下一个节点,则将上一个节点连接到下一个节点。然后将这个节点设置成最后一个节点。像我们刚才执行的演示代码:顺序放置了1,2,3,4。然后中间获取1。这是就走了这个方法,将1放置到了链表最后,变成了2,3,4,1。
参考文档
https://stackoverflow.com/questions/38974417/what-is-purpose-of-accessorder-field-in-linkedhashmap