在Spark SQL中, Catalyst优化器负责把查询语句最终转换为可以执行的Physical Plan.
Spark在Physical Plan的基础上还会再利用Tungsten(钨丝计划)进行一次优化
Tungsten主要围绕内核引擎做了两方面的改进:
- 数据结构设计
- 全阶段代码生成(WSCG, Whole Stage Code Generation)
Tungsten在数据结构方面的设计
相比Spark Core, Tungsten在数据结构方面做了两个较大的改进, 一个是紧凑的二进制格式Unsafe Row, 另一个是内存管理.
Unsafe Row: 二进制数据结构
Unsafe Row是一种字节数组, 它可以用来存储下图所示Schema为(userId, name, age, gender)的用户数据条目
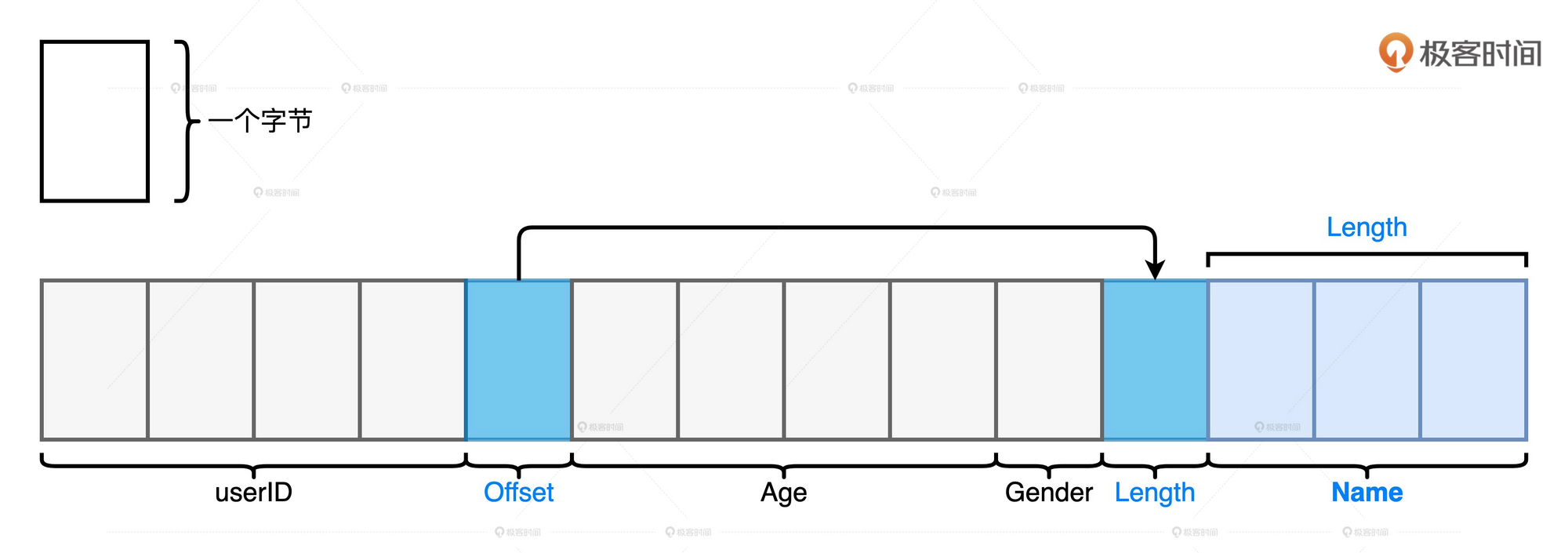 总的来说, 所有字段都会按照Schema中的顺序安放在数组中. 其中, 定长字段的值会直接安插到字节中, 而变长字段会先在Schema的相应位置插入偏移地址, 再把字段长度和字段值存储到靠后的元素中.
总的来说, 所有字段都会按照Schema中的顺序安放在数组中. 其中, 定长字段的值会直接安插到字节中, 而变长字段会先在Schema的相应位置插入偏移地址, 再把字段长度和字段值存储到靠后的元素中.
优点:
- 节省存储空间
使用JVM的对象存储时, 有对象头信息, 哈希码等其他额外的开销.
-
降低对象数量, 提高垃圾回收效率
以JVM的对象存储, 每条记录都需要创建一个对象, 这样会造成频繁GC, 降低了系统性能
UnsafeRow以字节数组的存储方式来消除存储开销, 并且仅用一个数组对象就完成来一条数据的封装, 显著降低了GC压力
基于内存页的内存管理???
为了统计管理Off Head和On Heap内存空间, Tungsten定义了统一的128位内存地址, 简称Tungsten地址.
Tungsten地址分为两部分: 前64位预留给Java Object, 后64位是偏移地址Offset.
虽然Off Heap和On Heap都是128位内存地址, 但是Off Heap和On Heap两块内存空间在寻址方式上截然不同.
对于On Heap空间的Tungsten地址来说, 前64位存储的是JVM堆内对象的引用或者说指针, 后64位Offset存储的是数据在该对象内的偏移地址. — 有指针不就找到对象了吗? 为什么还加一个数据的偏移地址.
而对于Off Heap, 由于Spark通过Java Unsafe API直接管理操作系统内存, 不存在内存对象的概念, 因此前64位存储的是null值, 后64位则用于在堆外空间中直接寻址操作系统的内存空间.
可以看出, 在Tungsten模式下, 管理On Heap会比Off Heap更加复杂, 这是因为在On Heap内存空间寻址堆内数据必需经过两步:
- 通过前64位的Object引用来定位JVM对象
- 结合Offset提供的偏移地址在堆内内存空间中找到所需的数据
JVM对象地址与偏移量的关系, 就好比是数组的起始地址与数组元素偏移地址之间的关系. 给定起始地址和偏移地址之后, 系统就可以迅速地寻址到数据元素.
如何理解WSCG
在Tungsten之前是如何计算的
内存计算的第二层含义: 在同一个Stage内部, 把多个RDD的compute函数捏合成一个, 然后把这个函数一次性的作用到输入数据上. 不过这种捏合方式采用的是迭代器嵌套的方式, 只是将多个函数嵌套, 并没有真正的融合为一个函数. 在Tungsten出现以前, Spark在运行时采用火山迭代模型来执行计算.
迭代器嵌套的计算模式会涉及两种操作: 一个是内存数据的随机存取, 另一个是虚函数调用. 这两种操作都会降低CPU的缓存命中率, 影响CPU的工作效率.
来举一个例子:
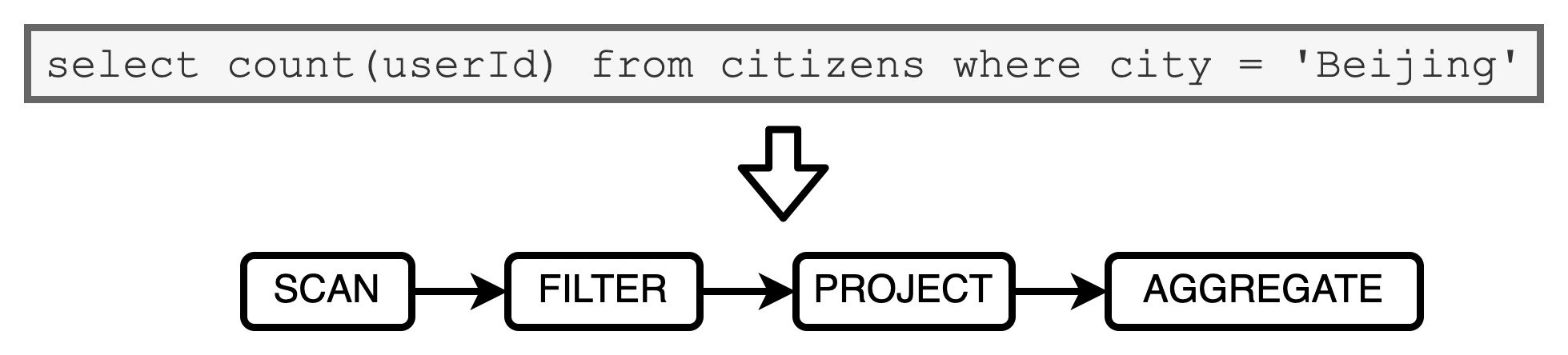 这个语句, 如果按照火山迭代模型来执行计算, 那么对于数据源重的每条数据, 语法树当中的每个操作符都需要完成如下步骤:
这个语句, 如果按照火山迭代模型来执行计算, 那么对于数据源重的每条数据, 语法树当中的每个操作符都需要完成如下步骤:
- 从内存中读取父操作符的输出结果作为输入数据
- 调用hasNext, next方法获取元素后, 以操作符逻辑处理数据.
- 将处理后的结果以统一的标准形式输出到内存, 供下游算子消费
WSCG
WSCG 指的是基于同一 Stage 内操作符之间的调用关系,生成一份“手写代码”,真正把所有计算融合为一个统一的函数
利用WSCG可以将上面的代码转换为如下类似的流程:
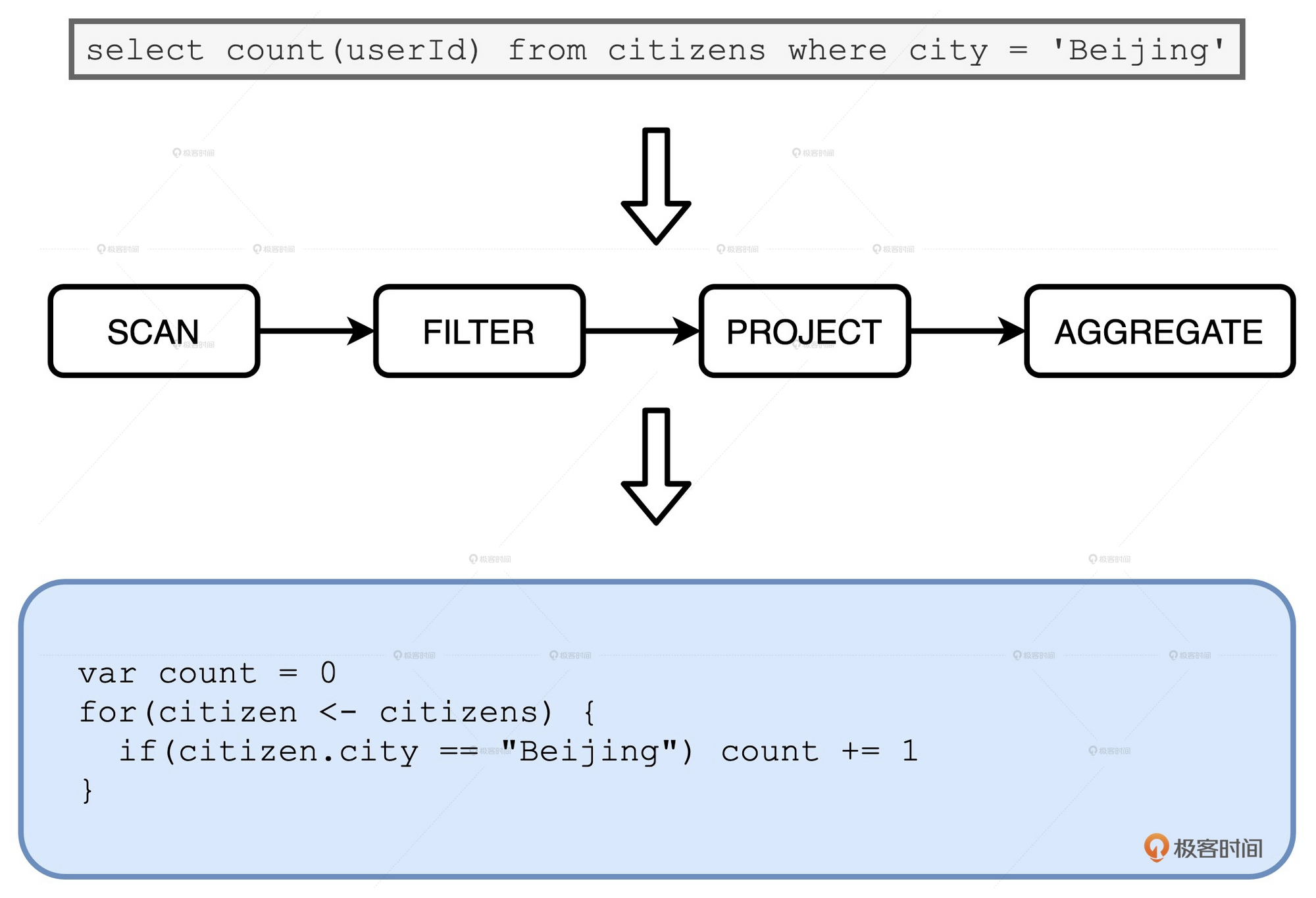 直接将4步流程转换成1步, 从而提高了性能. 数据只需计算1次即可, 也无需中间的缓存.
直接将4步流程转换成1步, 从而提高了性能. 数据只需计算1次即可, 也无需中间的缓存.
WSCG 机制的工作过程就是基于一份“性能较差的代码”,在运行时动态地(On The Fly)重构出一份“性能更好的代码”
WSCG是如何在运行时动态生成代码的
在刚刚的市民表查询例子中, 语法树从左到右有Scan, Filter, Project和Aggregate4个节点. 由于Aggregate会引入Shuffle切割Stage. 所以这4个节点会产生两个Stage.
WSCG是在同一个Stage内部生成手写代码. 所以我们来看前三个操作法Scan, Filter和Project构成的Stage
从中我们知道, Spark Plan在转换成Physical Plan之前, 会应用一系列的Preparation Rules. 这其中很重要的一环就是CollapseCodegenStages规则, 它的作用就是尝试为每一个Stage生成“手写代码”
总的来说, 手写代码的生成过程分为两个步骤:
- 从父节点到子节点, 递归调用doProduce, 生成代码框架
- 从子节点到父节点, 递归调用doConsume, 向框架填充每一个操作符的运算逻辑
用刚刚的Stage为例, 看下这个代码生成的过程:
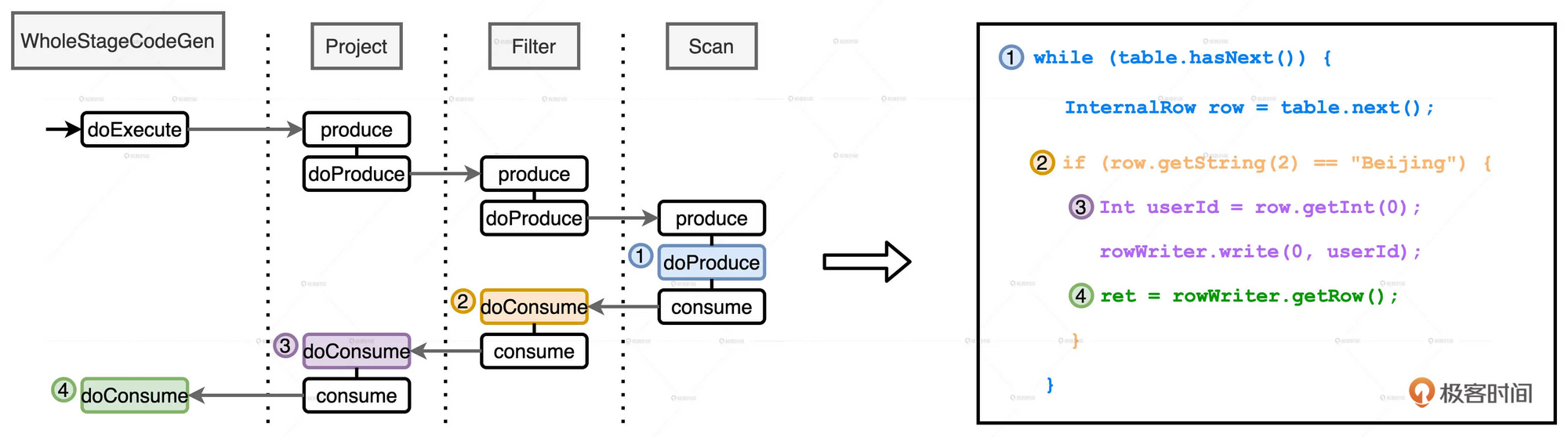 首先, 在Stage顶端节点也就是Project之上, 添加
首先, 在Stage顶端节点也就是Project之上, 添加WholeStageCodeGen节点.
WholeStageCodeGen节点通过调用doExecute来触发整个代码生成过程的计算.
doExecute 会递归调用子节点的doProduce函数, 直到遇到Shuffle Boundary为止. — 这里Shuffle Boundary指的是Shuffle边界, 要么是数据源, 要么是上一个Stage的输出.
在叶子节点(也就是Scan)调用的Produce函数会先把手写代码的框架生成出来, 图中右侧蓝色部分的代码.
然后, Scan中的doProduce函数会反向递归调用每个父节点的doConsume函数. 不同操作符在执行doConsume函数的过程中, 会把关系表达式转化成Java代码, 然后把这份代码潜入到刚刚的代码框架里. 比如图中橘黄色的doConsume生成的if语句, 其中包含了判断地区是否为北京的条件. 以及紫色的doConsume生成来获取必需字段userId的Java代码
就这样, Tungsten利用CollapseCodegenStages规则, 经过两次递归调用把Catalyst输出的Spark Plan加工成了一份“手写代码”. 并把这份手写代码交付给DAGScheduler, DAGScheduler再去协调TaskScheduler和SchedulerBackend, 完成分布式任务调度.