AQE(Adaptive query execution, 自适应查询引擎)引入了3个重要的特性:
- 自动分区合并
- 自动数据倾斜处理
- Join策略调整
AQE默认是禁用的, 调整spark.sql.adaptive.enabled参数来进行开启
自动分区合并
在Shuffle过程中, 由于数据分布不均衡, 导致Reduce阶段存在大量的小分区, 这些小分区的数据量很小, 但是调度的成本很大, 我们希望可以将这些小文件合并成大文件, 从而提高性能.
那么现在的问题就变成了:
-
如何判断一个分区是不是小, 需不需要进行合并?
-
合并的终止条件是什么? 我们不能无终止的合并下去.
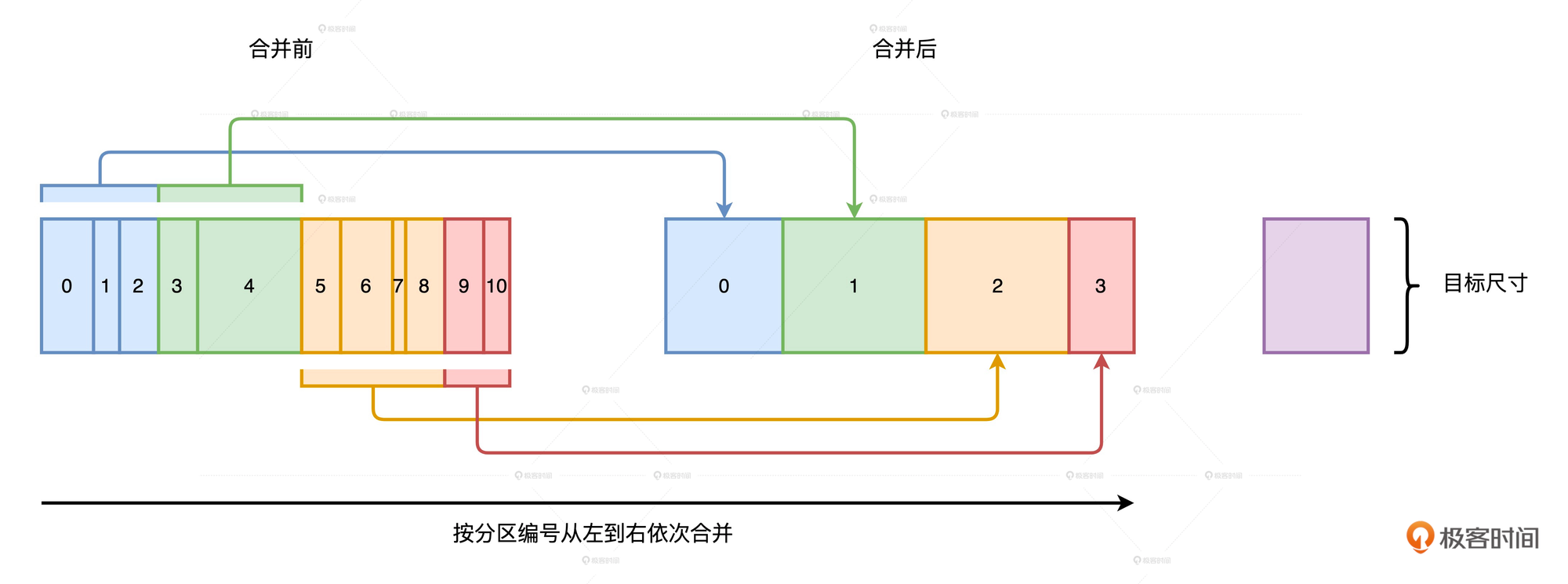 合并过程:
合并过程: -
AQE按照分区编号从左到右进行扫描, 扫描时记录分区尺寸.
-
当相邻分区的尺寸之和大于目标尺寸时, AQE就把这些扫描过的分区进行合并
-
继续向右扫描, 采用相同的算法, 按照目标尺寸合并剩余分区, 直至所有分区都处理完毕
AQE事先并不判断哪些分区足够小, 而是按照分区编号进行扫描, 当扫描量超过目标尺寸时, 就合并一次
目标尺寸由两个配置项来共同决定
- spark.sql.adaptive.advisoryPartitionSizeInBytes 开发者建议的目标尺寸
- spark.sql.adaptive.coalescePartitions.minPartitionNum 合并之后最小的分区数
假设我们Shuffle过后的数据大小为20GB, minPartitionNum设置为200, 这时每个分区的尺寸应该是20GB/200=100MB, advisoryPartitionSizeInBytes设置为200MB. 最终的目标尺寸会选择(100MB, 200MB)的最小值, 也就是100MB. 所以这个目标尺寸是由两个参数来共同决定的
自动数据倾斜处理
在进行Join时, AQE检测到有数据倾斜时, 会自动进行拆分操作, 把大分区拆分为多个小分区, 从而避免单个任务的数据处理量过大. Spark3.0的AQE只能在Sort Merge Join中自动处理数据倾斜.
AQE如何判定数据分区是否倾斜, 以及它是如何进行大分区的拆分的:
处理倾斜的几个参数:
- spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes 判断数据分区是否倾斜的最低阈值, 默认是256MB
- spark.sql.adaptive.skewJoin.skewedPartitionFactor 判定数据分区是否倾斜的比例系数, 默认值是5
- spark.sql.adaptive.advisoryPartitionSizeInBytes 以字节为单位, 拆分倾斜分区的数据粒度
首先, 只有当分区的尺寸大于skewedPartitionThresholdInBytes时才有资格被判定为倾斜分区.
然后, AQE统计所有分区大小并进行排序, 取中位数作为放大基数, 尺寸大于中位数的一定倍数时会被判定为倾斜分区. 中位数的放大倍数由参数skewedPartitionFactor控制
举个🌰:
假设数据表A有3个分区, 分区大小分为为80MB, 100MB和512MB. 这些分区按大小排序后的中位数是100MB. skewedPartitionFactor的默认值为5, 显然512MB>(100MB*5). 所以这个分区有可能被判定为倾斜分区.
当使用skewedPartitionThresholdInBytes的默认值时(256MB), 这个分区就会被判定为倾斜分区. 但是如果我们将其修改为600MB, 则这个分区就不会被判定成倾斜分区.
所以倾斜分区的判定也是同时依赖于两个参数的配置.
在判定一个分区属于倾斜分区后, 接下来就是进行拆分, 拆分时会使用advisoryPartitionSizeInBytes参数. 当我们将其设置为200MB时, 刚刚512MB的倾斜分区就会被拆分为3个分区(200, 200, 112). 拆分之后数据表就由原来的3个分区变成了5个分区. 每个分区的尺寸都不大于256MB(skewedPartitionThresholdInBytes).
Join策略调整
这里讲的策略调整是把引入Shuffle的Join(如Hash Join, Sort Merge Join) 降级成Broadcast Join
在AQE之前, 可以通过spark.sql.autoBroadcastJoinThreshold配置来设置Broadcast Join的阈值, 这个参数的默认值是10MB, 参与Join的两张表只要有一张数据表的尺寸小于10MB, 就可以将其转化为Broadcast Join.
这个参数有两个问题:
- 可靠性较差, 尽管明确设置了阈值, 而且小表数据量也在阈值内, 但是由于Spark对小表尺寸的误判, 导致没有进行Broadcast Join
- 预先设置广播阈值是一种静态的优化机制, 没办法在运行时动态的对数据关联进行降级. 一个典型例子是两个大表进行Join, 在逻辑优化阶段不满足广播阈值, 但是在运行时会对一张表对Filter, Filter完后的数据量完全满足广播阈值, 这种情况是无法转化为Broadcast Join的.
AQE很好的解决了这两个问题, AQE的Join策略调整是一种动态优化机制. 对于刚才的两张大表, AQE会在数据表完成过滤操作后动态计算剩余数据量, 当数据量满足广播条件时, AQE会重新调整逻辑计划, 在新的计划中将Shuffle Joins转化为Boradcast Join. 同时, 在运行时计算的数据量要比编译时准确的多, 所以AQE的动态Join策略相比静态优化更可靠、更稳定.
限制
- spark.sql.nonEmptyPartitionForBroadcastJoin
启用动态策略调整还有个前提, 就是要满足nonEmptyPartitionForBroadcastJoin参数的限制, 这个参数默认值是0.2, 大表过滤之后, 非空的数据分区占比要小于0.2, 才能成功触发Broadcast Join.