有哪些位置会发生OOM
首先我们要明确OOM是发生在Driver端还是Executor.
如果在Executor上, 是在哪个区域.
Driver端的OOM
Driver的主要职责是任务调度, 同时参与非常少量的任务计算.
Driver端的内存并没有明细的划分, 是整体的一块. 所以OOM问题只可能来自它设计的计算任务, 主要有两类:
- 创建小规模的分布式数据集: 通过parallelize、createDataFrame等API创建数据集
- 收集计算结果: 通过take、show、collect等算子把结果收集到Driver端
所以Driver端的OOM只会有这两类原因:
- 创建的数据集超过内存上限
- 收集的结果集超过内存上限
第一类原因不言而喻就是我们创建的数据集太大, 这类错误可以明显的在代码中找到进行修改.
而对于第二类原因, 有很多是间接调用了collect从而导致的OOM. 这类错误在代码中就没有那么明确的可以找到.
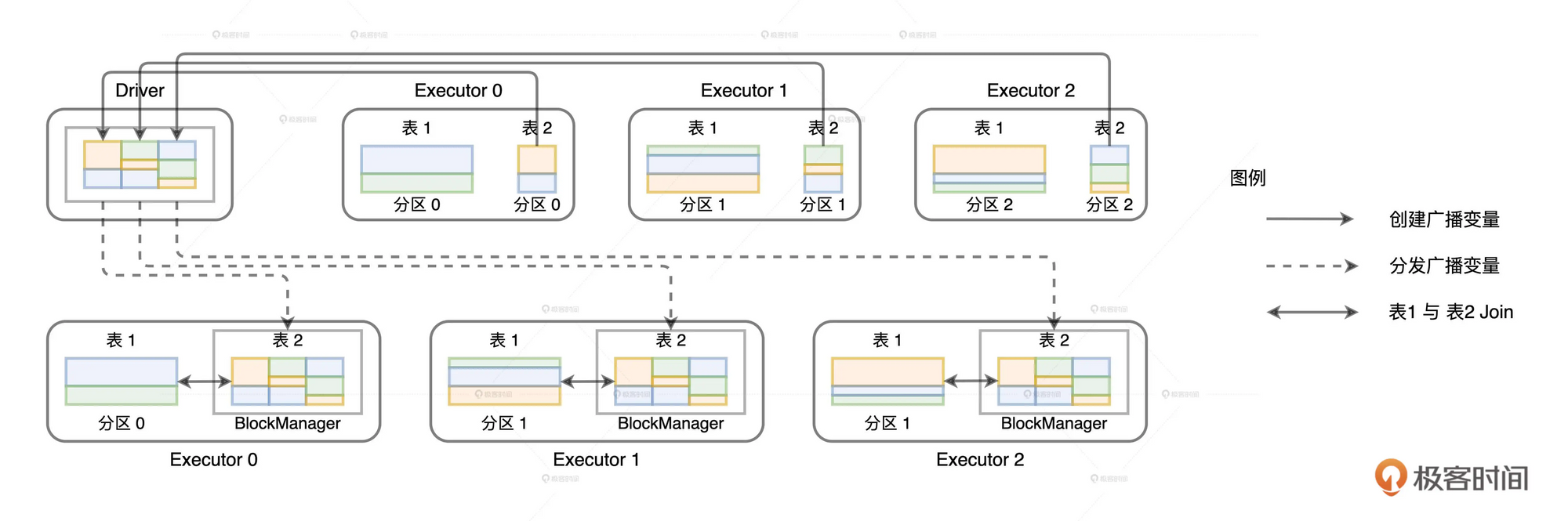
比如说我们对一个数据集进行broadcast操作, 在这个过程中就需要Driver从每个Executor的数据分片上把部分数据拉取到Driver端来构建全量数据集. 所以这个时候如果总大小超过Driver端内存就会报出OOM错误. 这个时候在日志中可以看到这样的错误:
|
|
如何修改配置
对于这两种情况, 都可以通过spark.driver.memory 配置项增大Driver的内存来避免OOM.
但是我们可以看下能否通过优化代码来解决这类问题
例如是否需要构建大数据量的数据集. 以及预估要广播变量的数据集大小, 从而可以更准确的调整内存大小
|
|
Executor端的OOM
Executor的内存主要分为4个区域:
- Reserved Memory 大小固定为300MB, 这部分是spark系统自己使用的内存
- Storage Memory 缓存内存区域, 数据集如果超过Storage Memory大小, 要么会直接抛弃(Memory_Only), 要么会缓存到磁盘(Memory_And_Disk)上
- User Memory 存储用户自定义的数据结构
- Execution Memory
我们可以看出Reserved Memory和Storage Memory是不会出现内存溢出的问题的. 如果在Executor端出现OOM那么只有可能出现在User Memory或者Execution Memory上.
User Memory
存储用户自定义的数据结构, 例如定义的一些变量值. 这些变量值会分发到每一个task上, 在同一个Executor上会有多个变量的副本, 这些副本都存储在User Memory区域中.
配置项
该区域大小计算公式为: spark.executor.memory * ( 1 - spark.memory.fraction)
所以我们可以调高每个Executor的memory大小, 或者调低(执行内存+缓存内存)的比例
Execution Memory
执行内存区域, 这个区域出错的概率比其他区域都高.
这个区域不仅于内存空间大小、数据分布有关, 还与Executor线程池和运行时调度有关.
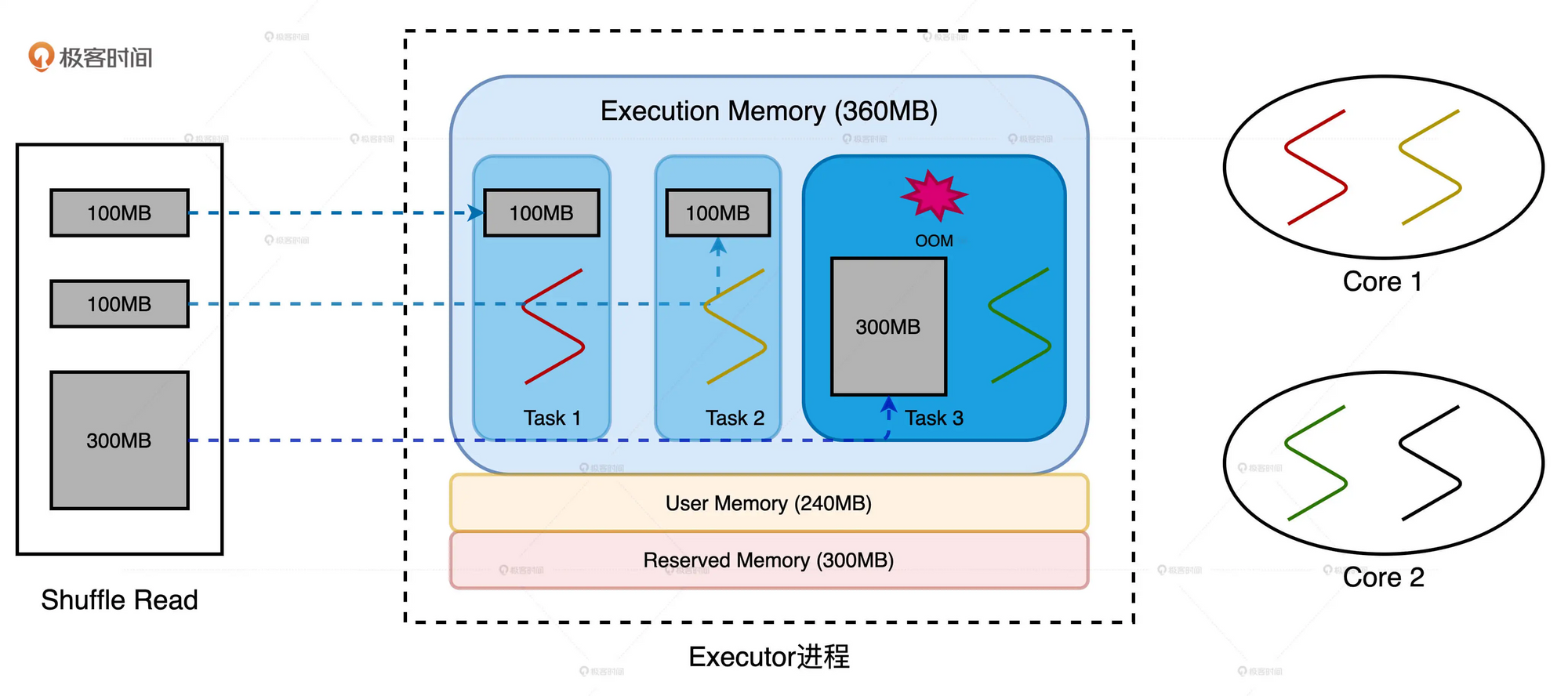
来看一下数据倾斜的例子:
我们现在的配置为: 2个CPU core, 每个core有两个线程, 内存大小为1GB. spark.executor.cores为3, spark.executor.memory为900MB.
在默认配置下, Execution Memory和Storage Memory为180MB( spark.memory.fraction=0.6, spark.memory.storageFraction=0.5. 还有300MB为Reserved Memory). Execution Memory的上限为360MB(没有RDD缓存时, 即占用了全部的Storage Memory).
节点在Reduce阶段拉取数据分片, 3个Reduce Rask对应的数据分片大小分别为100MB和300MB.
由于Executor线程池大小为3, 因此每个Reduce Task最多可以获取360/3=120MB的内存. 对于Task1, Task2可以顺利完成任务, 但是Task3的数据分片远超内存上限, 从而造成OOM.