广播变量
|
|
这段代码中的dict变量会被分发到每个task中, 由于每个executor上会运行多个task, 这样就造成了在每个executor上的数据冗余, 并且网络分发也会有消耗, 影响性能.
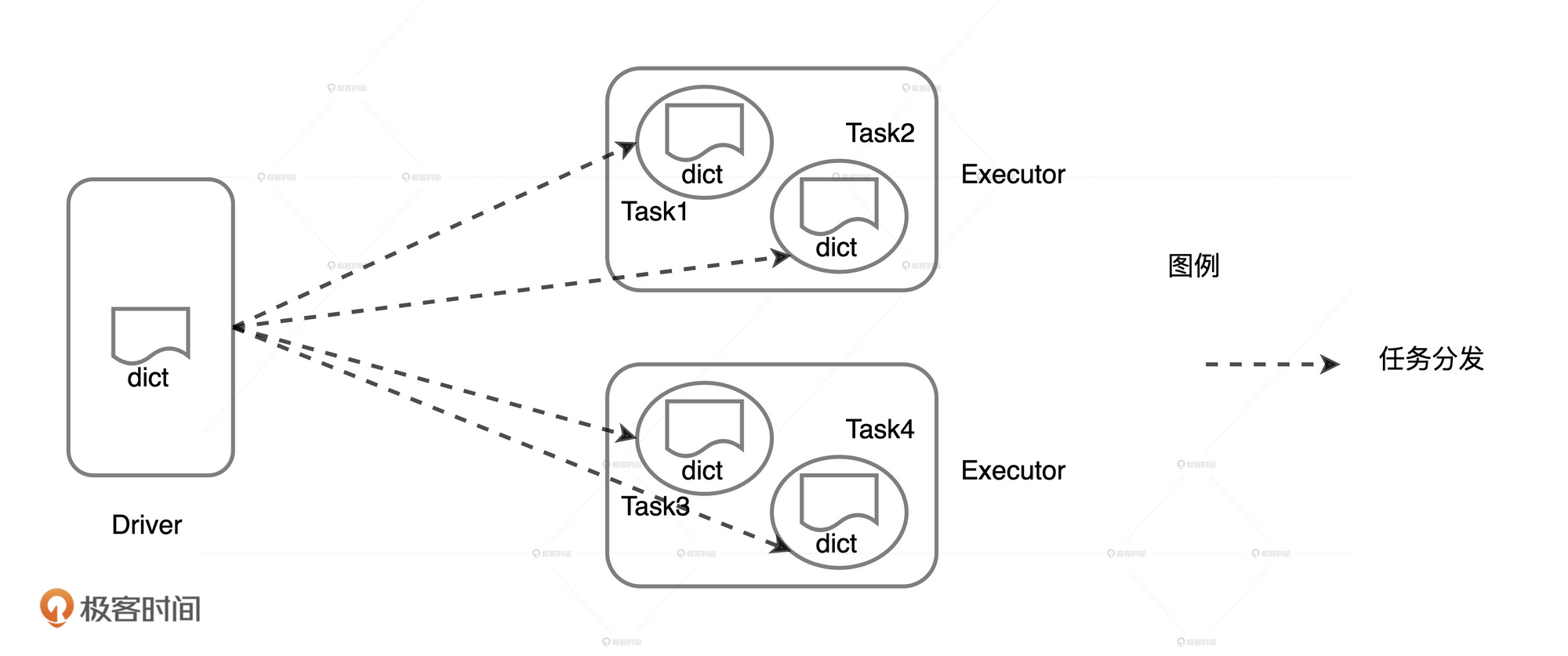
我们可以将这个dict变量作为广播变量, 分发到每个executor上, 每个task都从executor上获取数据.
|
|
在广播变量的运行机制下,封装成广播变量的数据,由 Driver 端以 Executors 为粒度分发,每一个 Executors 接收到广播变量之后,将其交给 BlockManager 管理
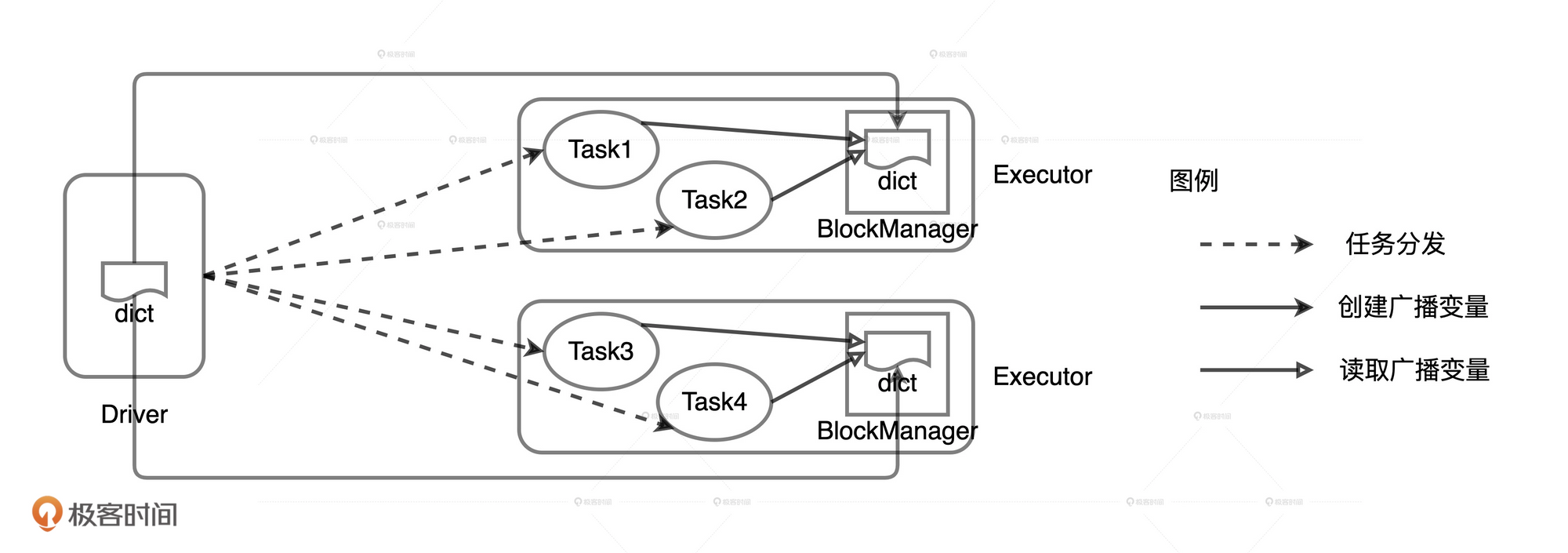
广播分布式数据集
在创建广播变量时, 由于变量的创建本来就在Driver上, 所以Driver直接把数据分发到各个Executor就可以了, 但是由于分布式数据集并不在Driver上, 它需要从各个Executor上拉取数据.
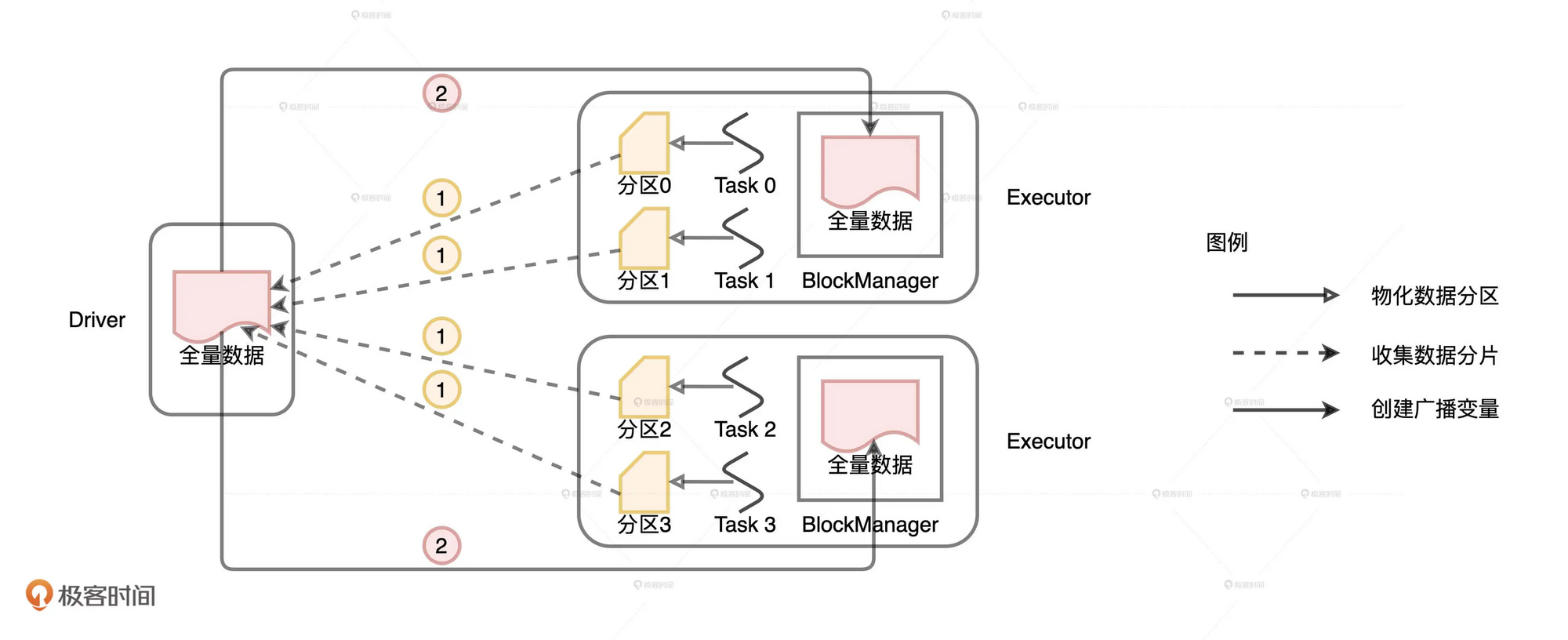
步骤为:
- Driver从所有的Executor拉取这些数据分区, 在本地构建全量数据 — 目前spark有个pr是关于将Driver获取到数据分布, 然后通知各个Executor进行拉取, 避免只有Drvier组装以后再一个个发送效率过低
- Driver把汇总好的全量数据分发给各个Executor, Executors 将接收到的全量数据缓存到存储系统的 BlockManager 中
相比于广播变量的创建, 广播分布式数据集的代价更大, 一是广播分布式数据需要Driver从各个Executor上拉取数据, 多了一步网络开销. 二是分布式数据的体量通常比广播变量大.
如何让Spark SQL选择Broadcast Joins
配置项
spark.sql.autoBroadcastJoinThreshold 默认值为10MB.
对于参与Join的两张表, 只要任意一张表的尺寸小于10MB, spark就会选择Broadcast Join.
但是这个size的判断并不是很准,
- 在source还未在内存中缓存时, 这时使用文件的大小
- 在source已经缓存在内存中, 这时可以直接判断数据的大小
下面这段代码可以大致判断出文件在运行时的大小
|
|
利用API强制广播
Join Hints
|
|
如果广播变量大小超过8GB, Spark会直接抛异常终端任务
并不是所有的Join类型都可以转化为Broadcast Joins