内存相关配置项设置并行度, 并行度用spark.default.parallelism和spark.sql.shuffle.partitions 两个参数确定.
- 对于没有明确分区规则的RDD, 使用
spark.default.parallelism来定义并行度 - 对于数据关联或聚合操作中可以使用
spark.sql.shuffle.partitions来指定Reduce端的分区数量
什么是并行度: 指的是分布式数据集被划分为多少份, 从而用于分布式计算. 并行度的出发点是数据, 它明确了数据划分的粒度. 并行度越高, 数据的粒度越细, 数据分片越多, 数据越分散.
并行计算任务: 指的是在任意时刻整个集群能够同时计算的任务数量. 并行计算任务的出发点是计算任务, 是CPU. 由CPU有关的三个参数共同决定. — 具体说来,Executor 中并行计算任务数的上限是 spark.executor.cores 与 spark.task.cpus 的商,暂且记为 #Executor-tasks,整个集群的并行计算任务数自然就是 #Executor-tasks 乘以集群内 Executors 的数量,记为 #Executors。因此,最终的数值是:#Executor-tasks * #Executors。
并行度决定了数据粒度, 数据粒度决定了分区大小, 分区大小决定每个计算任务的内存消耗.
CPU相关配置项
CPU的配置项主要包括 spark.cores.max、spark.executor.cores 和 spark.task.cpus 这三个参数.
- spark.cores.max — 限制整个job可以申请到的最大CPU数量, 当不设置时默认使用
spark.deploy.defaultCores这个参数(默认为Integer.MAX_VALUE, 也就是不限制) - spark.executor.cores — 设置单个executor可以使用的CPU资源, executor的数量可以通过($spark.cores.max / spark.executor.cores$)来确定
- spark.task.cpus — 设置单个task消耗的CPU核数, 一个executor上并行执行的task数量可以通过($spark.executor.cores / spark.task.cpus$)来确定
内存相关配置项
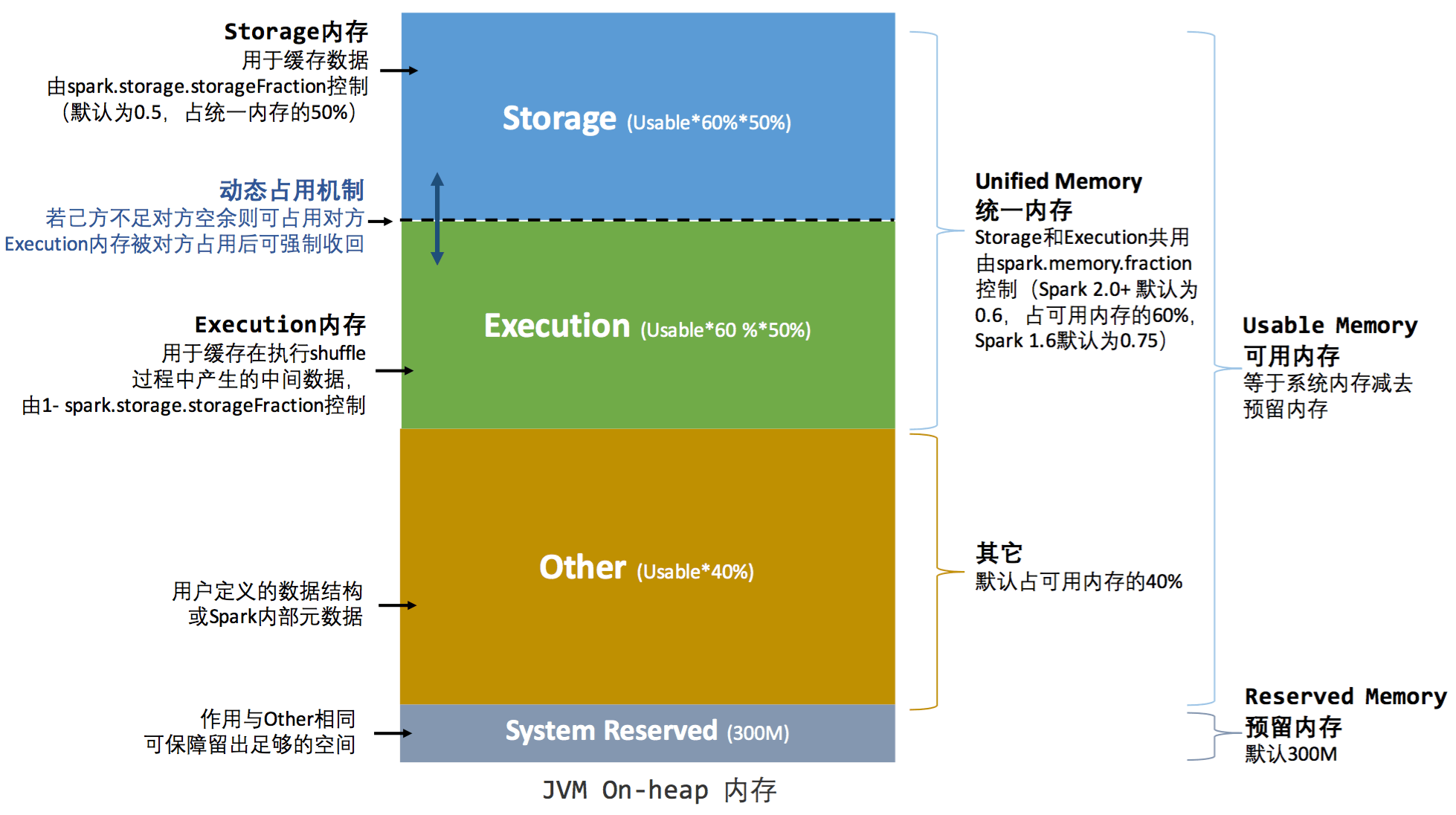
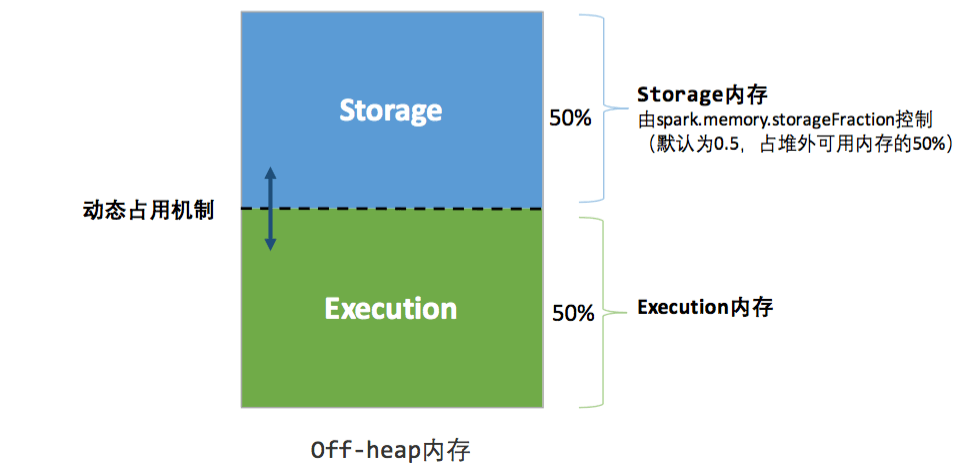 Spark管理的内存分为堆内内存和堆外内存.
Spark管理的内存分为堆内内存和堆外内存.
堆外内存又分为两个区域, Execution Memory和Storage Memory. 要想启用堆外内存, 需要将参数spark.memory.offHeap.enabled设置为true .然后再用spark.memory.offHeap.size 参数来指定堆外内存的大小
堆内内存也分为四个区域, 分别是Reserved Memory, User Memory, Execution Memory 和 Storage Memory
内存的基础配置项主要是5个:
- spark.executor.memory — 单个Executor中的堆内内存总大小
- spark.memory.offHeap.size — 单个Executor中堆外内存总大小(当spark.memory.offHeap.enable为true才生效)
- spark.memory.fraction — 堆内内存中, (用于缓存RDD和执行计算的内存之和)占可用内存的比例
- spark.memory.storageFraction — 用于缓存RDD的内存占比, 执行内存占比为$(1-spark.memory.storageFraction)$
- spark.rdd.compress — RDD缓存是否压缩, 默认不压缩
如何选择使用堆内内存或者是堆外内存
堆外内存虽然更好的进行内存占用统计, 不需要垃圾回收机制, 不需要序列化与反序列化. 但是终归还是有缺点, 不然我们就无脑的使用堆外内存了.
我们来看一个例子: 这个表有4个字段
- int类型的userId
- String类型的姓名
- int类型的年龄
- Char类型的性别
当我们需要用字节数组来存储这条记录时, 由于无法事先知道String类型的长度, 所以只能在存储位置使用真正存储位置的offset来代替, 在offset位置的第一位表示String的长度, 从而完成这条记录的存储.
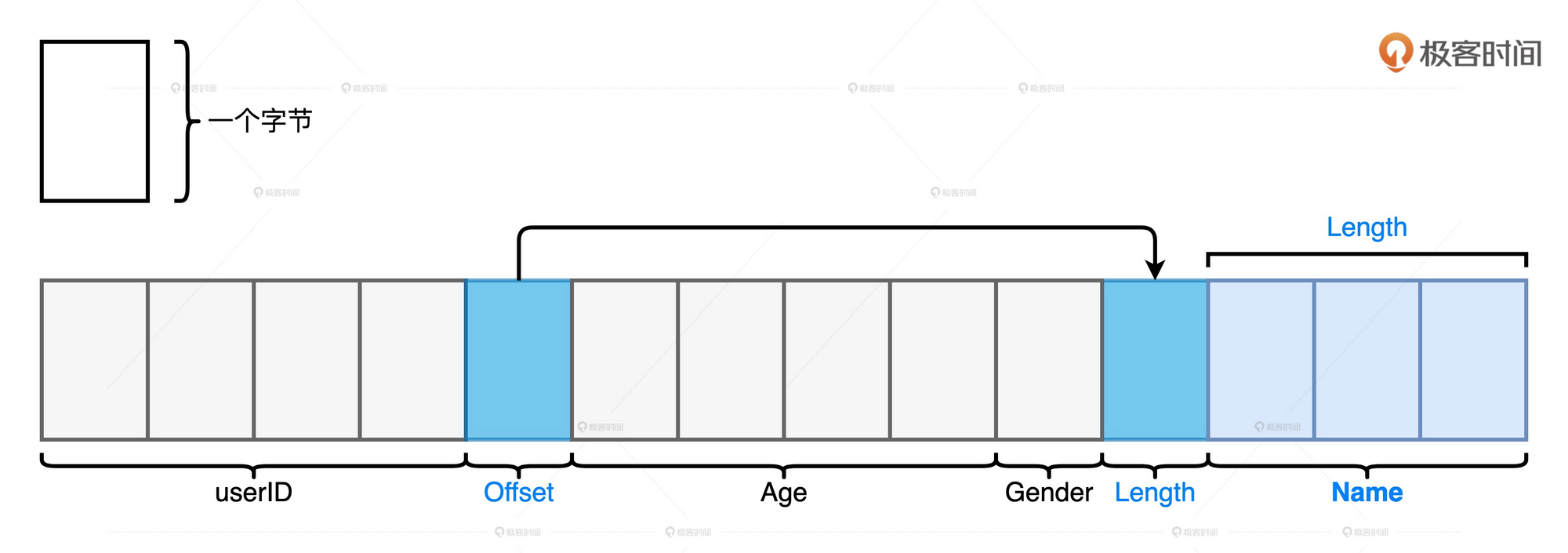 Spark的堆外内存也是使用这种方式来存储应用的数据. 这种方式比JVM的存储更加紧凑, 从而节省来空间. 但是当我们的Schema变得复杂后, 维护这样一条记录的指针和偏移地址变得越来越多, 让字段的访问效率大打折扣, 而且指针多了之后, 内存泄漏的风险也变大了. Spark直接管理堆外内存的成本就变得非常高.
Spark的堆外内存也是使用这种方式来存储应用的数据. 这种方式比JVM的存储更加紧凑, 从而节省来空间. 但是当我们的Schema变得复杂后, 维护这样一条记录的指针和偏移地址变得越来越多, 让字段的访问效率大打折扣, 而且指针多了之后, 内存泄漏的风险也变大了. Spark直接管理堆外内存的成本就变得非常高.
对于需要处理的数据集,如果数据模式比较扁平,而且字段多是定长数据类型,就更多地使用堆外内存。相反地,如果数据模式很复杂,嵌套结构或变长字段很多,就更多采用 JVM 堆内内存会更加稳妥
User Memory与Spark可用内存如何分配
现在Spark的spark.memory.fraction参数默认为0.6 , 也就是默认会有60%的内存归Spark调用, 剩余的40%为User Memory.
User Memory主要存储开发者自定义的数据结构或Spark内部元数据.
如果应用中自定义数据结构不多, 可以适当调大spark.memory.fraction参数, 从而提高Spark用于分布式计算和缓存分布式数据集的内存大小.
Execution Memory与Storage Memory如何平衡
统一内存管理模式下, 这两部分会互相占用. 当Execution Memory占用Storage Memory后, 需要执行完成后才会被释放, 而当Storage Memory占用Execution Memory时, 当Execution Memory需要则需要理解释放掉.
如果应用是“缓存密集型”的, 即需要反复遍历同一份分布式数据, 这个时候将数据缓存下来则可以提高效率. 即可以提高spark.memory.storageFraction
但是, 还需要注意这两个之间的平衡.
当Storage Memory调大之后, 意味着Execution Memory变小了. 那么在执行关联, 排序, 聚合等需要消耗执行内存的任务时, 就会变慢.
由于Execution Memory变小, 在堆内创建新对象时, 由内存不足造成的垃圾回收也会影响执行效率.
还有一种方法是在进行缓存是将数据进行压缩, 这样相同的内存空间下就可以存储更多的数据, 可以修改spark.rdd.compress参数, 默认情况下是不使用压缩的
磁盘相关配置项
spark.local.dir 这个参数可以运行开发者设置存储_RDD cache落盘数据块_和_Shuffle中间文件_的磁盘目录
Shuffle类配置项
Shuffle分为Map和Reduce两个阶段. Map阶段按照Reducer的分区规则, 将中间数据写入到磁盘中, 然后Reduce阶段从各个Map节点拉取数据, 根据计算规则进行计算.
spark.shuffle.file.buffer 和 spark.reducer.maxSizeInFlight 两个参数可以分别控制Map端和Reduce端的读写缓冲区大小.
Map阶段, 由于是先将数据写到内存(写缓存区)中, 当内存不足时再写到磁盘, 所以可以调大内存(写缓冲区)来减少I/O次数, 从而提高整体性能. 这个时候就需要调大spark.shuffle.file.buffer 参数.
Reduce阶段, Spark通过网络从不同Map节点的磁盘中拉取中间文件, 然后以数据块的形式暂存到Reduce节点的读缓冲区. 读缓冲区越大, 可以暂存的数据块也就越多, 拉取数据所需的网络请求次数也就越少, 单次请求的网络吞吐越高, 网络I/O的效率也就越高. 这个时候可以调节spark.reducer.maxSizeInFlight 来调大读缓冲区的大小, 提高性能.
跳过排序
spark从1.6版本开始, Spark统一采用Sort shuffle manager来管理Shuffle操作, 这时不管计算是否真的需要排序, 都会在Map阶段和Reduce阶段进行排序.
所以在不需要聚合,也不需要排序的计算场景中,我们就可以通过设置 spark.shuffle.sort.bypassMergeThreshold 的参数,来改变 Reduce 端的并行度(默认值是 200)。当 Reduce 端的分区数小于这个设置值的时候,我们就能避免 Shuffle 在计算过程引入排序。