不同的缓存级别
Spark的cache支持多种缓存级别, 比如MEMORY_AND_DISC_SER_2、MEMORY_ONLY等等. 这些值是这几部分构成的:
- 存储介质: 内存还是磁盘, 还是两者都有
- 存储形式: 存储对象值还是序列化的字节数组, 带SER字样的表示以序列化方式存储, 不带SER表示采用对象值
- 副本数量: 拷贝数量, 没有数字默认为1份副本
Spark对RDD.cache函数默认使用MEMORY_ONLY, 对DataFrame.cache默认使用MEMORY_AND_DISK.
缓存的计算过程
在MEMORY_AND_DISK模式下, Spark会优先尝试把数据集全部缓存到内存, 内存不足的情况下, 再把剩余的数据落盘到本地.
MEMORY_ONLY则不管内存是否充足, 一股脑的把数据缓存到内存.
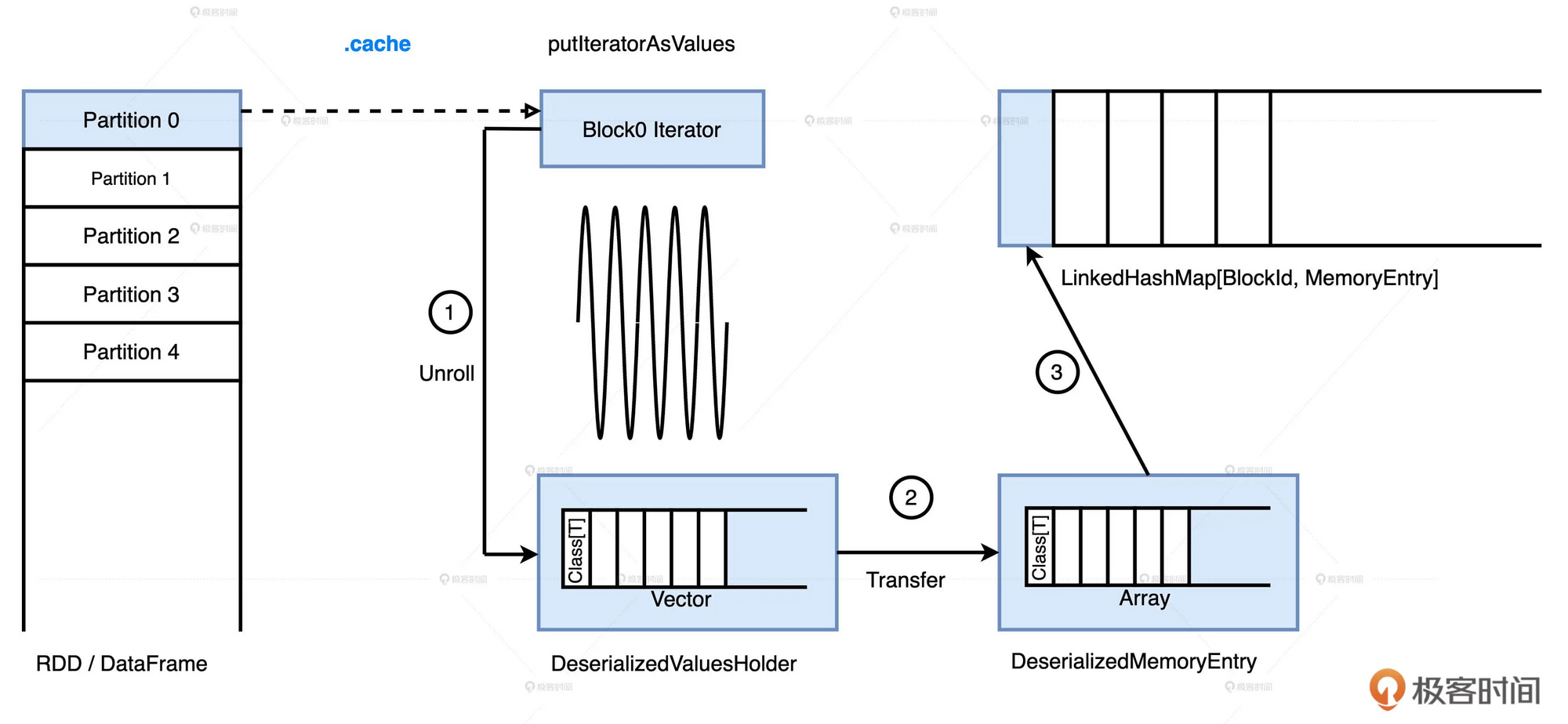
- 无论是RDD还是DataFrame, 它们的数据分片都是以迭代器Iterator的形式存储的. 因此, 要把数据缓存下来, 就要把迭代器展开成实实在在的数据值, 这一步叫做Unroll.
- 展开的对象暂存在一个叫做ValuesHolder的数据结构里, 然后转化为MemoryEntry. 这里转化的实现方式是toArray, 因此它不产生额外的内存开销, 这一步叫做Transfer.
- 最终, MemoryEntry和与之对应的BlockID, 以K, V的形式存储到哈希字典(LinkedHashMap)中
当分布式数据集所有的数据分片都从Unroll到Transfer, 再到注册哈希字典后, 数据在内存的缓存过程就结束了
缓存的销毁过程
将数据缓存进内存时, 如果发现内存不足, 则需要根据LRU算法来驱逐(Eviction)一些数据分片
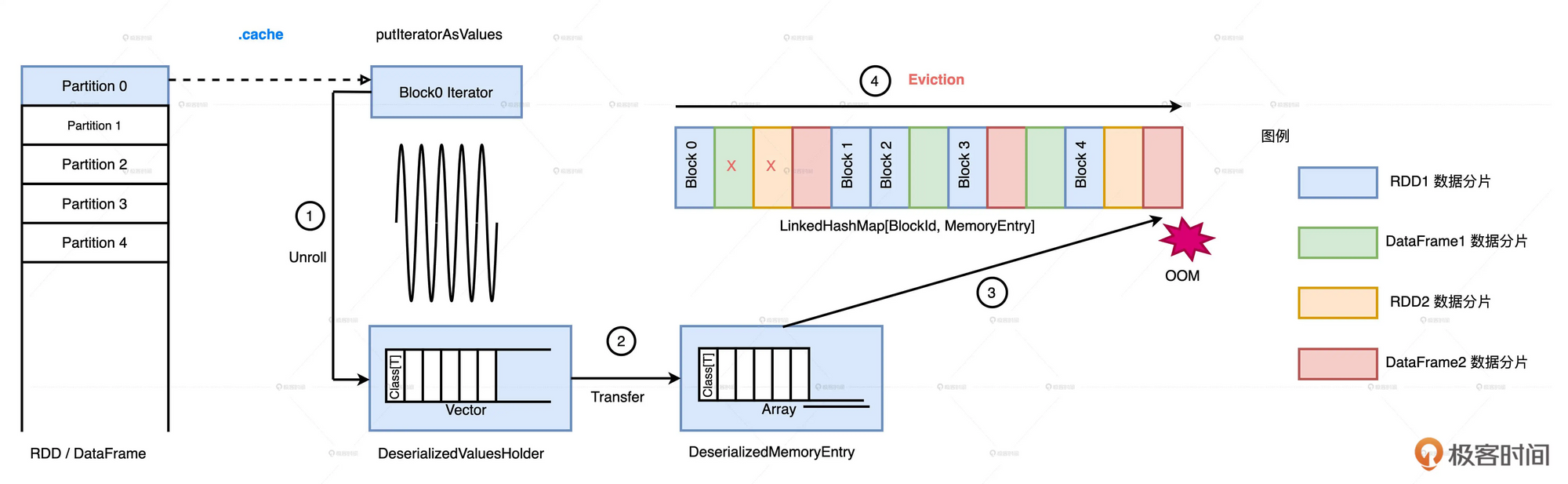
由于Spark在存储MemoryEntry时使用了LinkedHashMap的数据结构, 所有可以很容易的找到最近最少使用的Block(链表头部).
Spark当试图缓存一个数据分片, 却发现可用内存不足时, 会对LinkedHashMap从头扫描, 当扫描过的MemoryEntry尺寸之和大于要写入的数据分片时, 将这些数据给删除掉.
在进行缓存清楚时, 同属一个RDD的MemoryEntry不会被选中
在缓存清除的过程中, Spark遵循两个基本原则
- LRU, 按照元素的访问顺序, 优先清除那些“最近最少访问”的MemoryEntry
- 同属一个RDD的MemoryEntry不会被清除
数据丢失
在Memory_Only的模式下, 尽管有缓存销毁这个环境, 但是总会“驱无可驱”, 这个时候, Memory_Only就会放弃剩余的数据分片, 造成数据丢失.
Cache的注意事项
cache是惰性操作, 在调用cache只会, 需要用Action算子触发缓存的物化过程.
假如我们使用了take, show, first这几个action算子, Spark并不会缓存所有的元素, 只会缓存用到的几个元素, 例如take算子只缓存take的20条记录.
我们需要使用count这类的全局操作算子. 才能保证cache的完整性.
Cache Manager要求两个查询的Analyzed Logical Plan必须完全一致, 才能对DataFrame的缓存进行复用.
缓存清理
可以手动调用unpersist来清理弃用的缓存数据, 它支持同步、异步两种模式
异步模式: 调用unpersist() 或是 unpersist(false)
同步模式: 调用unpersist(true)
在异步模式下,Driver 把清理缓存的请求发送给各个 Executors 之后,会立即返回,并且继续执行用户代码,比如后续的任务调度、广播变量创建等等。
在同步模式下,Driver 发送完请求之后,会一直等待所有 Executors 给出明确的结果(缓存清除成功还是失败)。各个 Executors 清除缓存的效率、进度各不相同,Driver 要等到最后一个 Executor 返回结果,才会继续执行 Driver 侧的代码