在2.0版本之前, Spark SQL仅仅支持启发式、静态的优化过程, 启发式的优化又叫RBO(Rule Based Optimization, 基于规则的优化), 它基于一些规则和策略实现, 如谓词下推、列剪枝. 这些规则和策略来源于数据库领域已有的应用经验. 启发式的优化是一种经验主义.
经验主义的弊端是对待相似的问题和场景都使用同一种套路.
在2.2版本中推出了CBO(Cost Based Optimization, 基于成本的优化), 特点是“实事求是”, 基于数据表的统计信息(如表大小、数据列分布)来选择优化策略. CBO支持的统计信息很丰富, 比如数据表的行数、每列的基数(Cardinality)、空间值、最大值、最小值和直方图等等. 因为有统计数据做支持, 所以CBO选择的优化策略往往优于RBO选择的优化规则.
但是CBO也有三个方面的缺点: 窄、慢、静.
- 窄 : 指的是适用面太窄, CBO仅支持注册到Hive Metastore的数据表
- 慢: 指的是统计信息的搜集效率比较低. 对于注册到Hive Metastore的数据表, 开发者需要调用ANALYZE TABLE COMPUTE STATISTICS语句收集统计信息, 而各类信息的收集会消耗大量时间
- 静: 指的是静态优化, 这一点与RBO一样, CBO结合各类统计信息指定执行计划, 一旦执行计划交付运行, CBO的使命就算完成了. 也就是说如果在运行时数据分布发送动态变化, CBO先前制定的执行计划并不会跟着调整、适配
AQE是什么
Spark在3.0推出了AQE(Adaptive Query Execution, 自适应查询执行). AQE是Spark SQL的一种动态优化机制, 在运行时, 每当Shuffle Map阶段执行完毕, AQE都会结合这个阶段的统计信息, 基于既定的规则动态的调整、修正尚未执行的逻辑计划和物理计划, 来完成对原始查询语句的运行时优化.
AQE的优化机制触发的时机是Shuffle Map阶段执行完毕. 也就是说, AQE优化的频次与执行计划中Shuffle的次数一致. 如果查询语句没有引入Shuffle操作, 那么Spark SQL是不会触发AQE的.
AQE依赖的统计信息是什么:
AQE赖以优化的统计信息与CBO不同, 这些统计信息并不是关于某张表或是哪个列, 而是Shuffle Map阶段输出的中间文件. 每个Map Task都会输出以data为后缀的数据文件, 还有以index为结尾的索引文件, 这些文件统称为中间文件. 每个data文件的大小、空文件数量与占比、每个Reduce Task对于的分区大小, 所有这些基于中间文件的统计值构成了AQE进行优化的信息来源.
AQE还会从运行时获取统计信息, 在条件允许的情况下, 优化决策会分别作用到逻辑计划和物理计划.
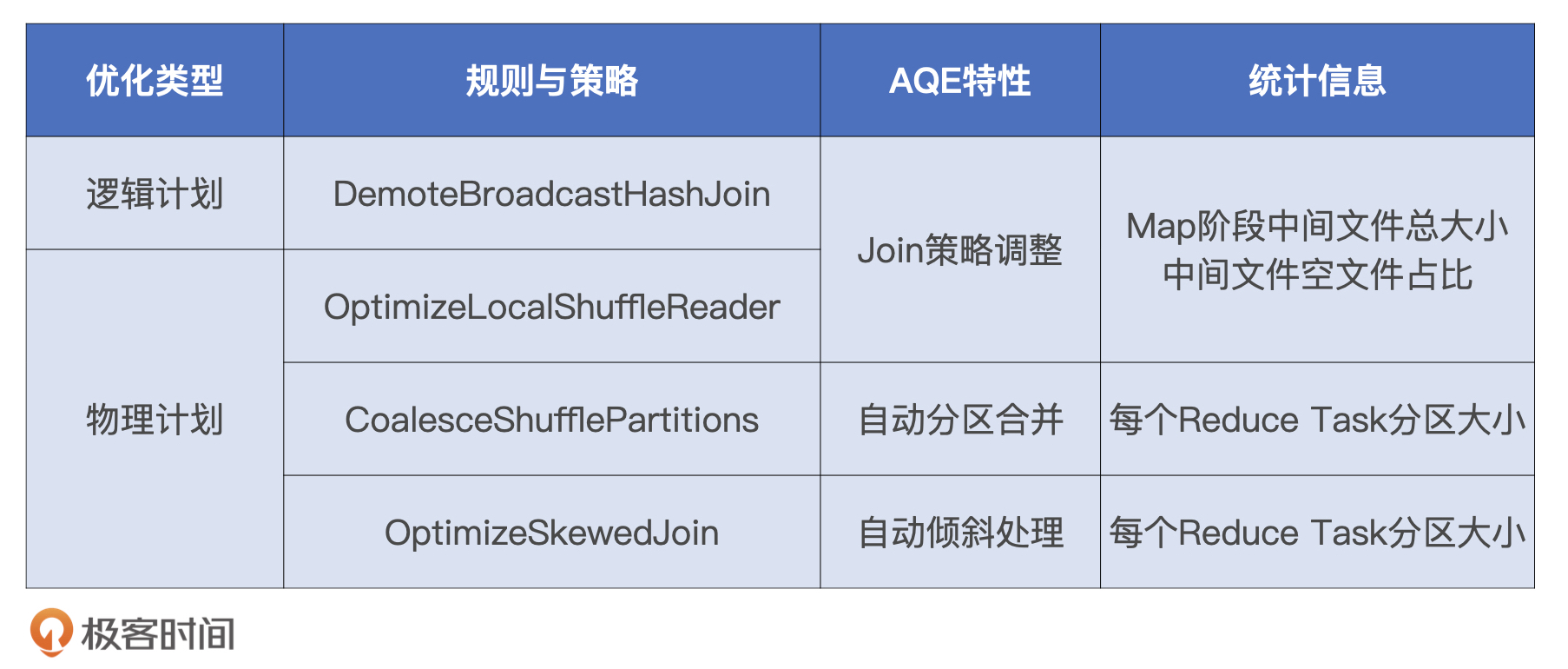
AQE既定的规则和策略主要有4个, 分为1个逻辑优化规则和3个物理优化策略
如何用好AQE
首先回顾一下AQE动态优化的过程:
- Join策略调整 : 如果某张表在过滤之后, 尺寸小于广播变量阈值, 这张表参与的数据关联就会从Shuffle Sort Merge Join降级(Demote)为执行效率更高的Broadcast Hash Join.
- 自动分区合并 : 在Shuffle之后, Reduce Task数据分布参差不齐, AQE将自动合并过小的数据分区
- 自动倾斜处理 : 结合配置项, AQE自动拆分Reduce阶段过大的数据分区, 降低单个Reduce Task的工作负载
Join策略调整
这个特性设计了一个逻辑规则和一个物理策略, 它们分别是DemoteBroadcastHashJoin和OptimizeLocalShuffleReader.
DemoteBroadcastHashJoin规则的作用, 是把Shuffle Joins降级为Broadcast Joins. 需要注意的是, 这个规则仅适用于Shuffle Sort Merge Join这种关联机制, 其他机制如Shuffle Hash Join、Shuffle Nested Loop Join都不支持. 对于参与Join的两张表来说, 在它们分别完成了Shuffle Map阶段的计算之后, DemoteBroadcastJoin会判断中间文件是否满足如下条件
- 中间文件尺寸总和小于广播阈值 spark.sql.autoBroadcastJoinThreshold
- 空文件占比小于配置项 spark.sql.adaptive.nonEmptyPartitionRatioForBroadcastJoin
只要有任意一张表的统计信息满足这两个条件, Shuffle Sort Merge Join就会降级为Broadcast Hash Join.
AQE依赖的统计信息来自于Shuffle Map阶段生成的中间文件, 这意味着AQE在开始优化之前, Shuffle操作就已经执行过半了.
OptimizeLocalShuffleReader物理策略可以在大表已经完成Shuffle Map阶段后, 不再进行网络分发, 将Reduce Task改为就地读取本地节点的中间文件, 完成与小表的关联操作.
OptimizeLocalShuffleRead物理策略的生效由一个配置项spark.sql.adaptive.localShuffleRead.enable 决定, 默认值为True.
自动分区合并
在Reduce阶段, 当Reduce Task从全网把数据拉回, AQE按照分区编号的顺序, 依次把小于目标尺寸的分区合并在一起.
目标分区尺寸由以下两个参数共同决定:
- spark.sql.adaptive.advisoryPartitionSizeInBytes 由开发者指定分区合并后的推荐尺寸
- spark.sql.adaptive.coalescePartitions.minPartitionNum 最小分区数量, 分区合并后, 分区数不能小于该值
在Shuffle Map阶段完成之后, AQE优化机制被触发, CoalesceShufflePartitions策略“无条件”地被添加到新的物理计划中. 读取配置项、计算目标分区大小、依序合并相邻分区这些计算逻辑, 在Tungsten WSCG的作用下融合进“手写代码”于Reduce阶段执行.
自动倾斜处理
于自动分区合并相反, 自动倾斜处理的操作是“拆”, 在Reduce阶段, 当Reduce Task所需处理的分区尺寸大于一定阈值时, 利用OptimizeSkewedJoin策略, AQE会把大分区拆分成多个小分区.
倾斜分区和拆分粒度由以下配置项决定:
- spark.sql.adaptive.skewJoin.skewedPartitionFactor 判断倾斜的膨胀系数
- spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes 判断倾斜的最低阈值
- spark.sql.adaptive.advisoryPartitionSizeInBytes 以字节为单位, 定义拆分粒度
自动倾斜处理的拆分操作也是在Reduce阶段执行的. 在同一个Executor内部, 本该由一个Task去处理的大分区, 被AQE拆分成多个小分区并交由多个Task去计算. 这样Task之间的计算负载就可以得到平衡. 但是, 这并没有解决Executors之间的负载均衡问题.
这里的拆分只是将一次执行的大任务分成多个小任务, 但是这些任务还都是在一个Executor上执行的, 从总体来看, 还是存在单个Executor的倾斜问题.
问题:
-
对于Join的两张表, 如果表1有倾斜, 表2不存在倾斜, 那么只需要对表1进行拆分, 但是这时为了保证关联关系不被破坏, 还需要对表2对应的数据分区做复制.
-
如果两张表都存在倾斜. 这时将表1拆分为2份, 表2拆分为2份. 为了不破坏逻辑上的关联关系
表1、表2拆分出来的分区还要各自复制一份.
当左表拆除M个分区, 右表拆分出N个分区, 那么每张表都需要保持M*N份分区数据, 才能保证关联逻辑的一致性. 当M, N逐渐变大时, AQE处理数据倾斜所需要的计算开销将会面临失控的风险
总的来说, 当应用中的数据倾斜比较简单, 比如虽然有倾斜但数据分布相对均匀, 或是关联计算中只有一边有倾斜, 我们完全可以依赖AQE的自动倾斜处理机制. 但是, 在应用中倾斜十分复杂时就需要衡量AQE的自动倾斜处理与手动处理倾斜之间的关系.
AQE小结
AQE是Spark SQL的一种动态优化策略, 它的诞生解决了RBO、CBO, 这些启发式、静态优化机制的局限性.
AQE在Shuffle Map阶段执行完毕, 都会结合这个阶段的统计信息, 根据既定的规则和策略动态的调整、修正尚未执行的逻辑计划和物理计划, 从而完成对原始查询语句的运行时优化. 因此, 只有当查询语句会引入Shuffle操作时, Spark SQL才会触发AQE.
AQE支持的三种优化特性分别是Join策略调整、自动分区合并和自动倾斜处理
关于Join策略调整, DemoteBroadcastHashJoin规则仅仅适用于Shuffle Sort Merge Join这种关联机制, 对于其他Shuffle Joins类型, AQE暂不支持把它们转化为Broadcast Joins. 其次, 为了确保AQE的Join策略调整正常运行, 要确保spark.sql.adaptive.localShuffleReader.enabled配置为开启状态
关于自动分区合并, 在Shuffle Map阶段完成之后, 结合分区推荐尺寸与分区数量限制, AQE会自动帮我们完成分区合并的计算过程
关于AQE的自动倾斜处理, 它只能以Task为粒度缓解数据倾斜, 并不能解决不同Executors之间的负载均衡问题.