执行内存抢占规则,
在同一个 Executor 中,当有多个(记为 N)线程尝试抢占执行内存时,需要遵循 2 条基本原则
- 执行内存总大小(记为 M)为两部分之和,一部分是 Execution Memory 初始大小,另一部分是 Storage Memory 剩余空间
- 每个线程分到的可用内存有一定的上下限,下限是 M/N/2,上限是 M/N,也就是均值
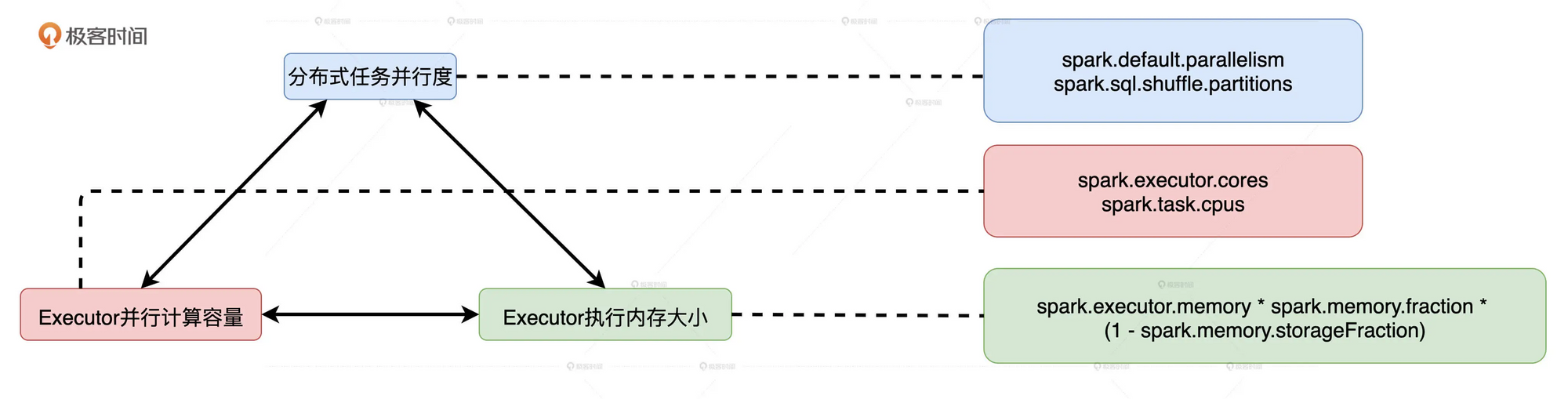
并行度、并发度与执行内存的关系
并行度
明确了数据的划分粒度, 并行度越高, 数据的粒度越细, 数据分片越多, 数据越分散.
并行度可以通过两个参数来设置: 分别是 spark.default.parallelism 和 spark.sql.shuffle.partitions. 前者用于设置 RDD 的默认并行度, 后者在 Spark SQL 开发框架下, 指定了 Shuffle Reduce 阶段默认的并行度.
并发度
****一个Executor内部可以同时运行的最大任务数量.
由Executor的线程池大小(spark.executor.cores)除以每个任务执行期间需要消耗的线程数(spark.task.cpus)得到. spark.task.cpus默认是1, 通常不会调整, 所以并发度基本由spark.executor.cores参数决定
就Executor的线程池来说, 尽管线程本身可以复用, 但每个线程同一时间只能计算一个任务, 每个任务负责处理一个数据分片. 因此, 在运行时, 线程、任务与分区是一一对应的关系.
分布式任务由Driver分发给Executor后, Executor将Task封装为TaskRunner, 然后将其交给可回收缓存线程池(newCachedThreadPool). 线程池中的线程领取到TaskRunner之后, 向Execution Memory申请内存, 开始执行任务.
执行内存
堆内执行内存的初始值:
spark.executor.memory * spark.memory.fraction * (1- spark.memory.storageFraction)
executor的内存 * 执行内存和缓存内存占总内存系数 * (1-缓存内存系数)
堆外执行内存:
spark.memory.offHeap.size * (1-spark.memory.storageFraction)
堆外内存大小 * (1 - 缓存内存系数)
在统一内存管理模式下, 当Storage Memory没有被RDD缓存占满的情况下, 执行任务可以动态大的抢占Storage Memory. 可分配的执行内存总量会随着缓存任务和执行任务的此消彼长而动态变化. 但无论怎么变, 可用的执行内存总量, 都不会低于配置项设定的初始值.
如何提升CPU效率
CPU低效原因之一: 线程挂起
在给定执行内存总量M和线程总数N的情况下, 为了保证每个线程都有机会拿到适量的内存去处理数据, Spark用HashMap的数据结构, 以(K, V)的方式来记录每个线程消耗的内存大小, 并确保所有的Value值都不超过M/N. 但是在某些极端情况下, 有些线程申请不到所需的内存空间, 能拿到的内存合计还不到M/N/2. 这个时候Spark就会把线程挂起, 直到其他线程释放了足够的内存空间为止.
即便能保证每个线程能拿到的内存上限是M/N, 也就是内存总量对线程数取平均值. 但是由于以下3方面的变化, 造成了有些线程连M/N/2的资源都拿不到
-
动态变化的执行内存总量M
M的下限是Execution Memory初始值, 上限是Execution Memory + Storage Memory. 在应用刚开始时, 由于没有RDD缓存占用Storage Memory, 所以取这个上限, 但是随着RDD缓存的填充, M的值就会下降
-
动态变化的并发度N‘
上下限公式中计算用的N不是线程总数N, 而是当前的并发度N’. 尽管一个Executor中有N个CPU线程 但是这个N个线程不一定都在干活. 在Spark任务调度的过程中, 这个N个线程不一定可以同时拿到分布式任务, 所以先拿到任务的线程就可以申请更多的内存.
-
分布式数据集的数据分布
每个Task申请多少内存取决于需要处理的数据分片多大, 如果分片过大, 那么就需要申请大内存, 如果内存不足, 就造成了线程挂起. 如果分布式数据集的并行度设置得当, 因任务调度滞后而导致的线程挂起问题就会得当缓解.
CPU低效原因之二: 调度开销
对于每一个分布式任务, Driver会将其封装为TaskDescription, 然后分发给各个Executor. TaskDescription包含着与任务运行有关的所有信息, 如任务ID、要处理的数据分片ID、开发者添加的本地文件和Jar包、任务属性、序列化的任务代码等等. Executor接受到TaskDescription后, 需要首先对TaskDescription反序列化才能读取任务信息, 然后将任务代码再反序列化得到可执行代码, 最后结合其他任务信息创建TaskRunner.
每个任务的调度都需要Executor消耗CPU去执行上述一系列的操作步骤. 数据分片与线程、执行任务一一对应, 当数据过于分散, 任务调度上的开销就与数据处理的开销在相同数量级.
因此,在给定 Executor 线程池和执行内存大小的时候,我们可以参考上面的算法,去计算一个能够让数据分片平均大小在(M/N/2, M/N)之间的并行度,这往往是个不错的选择