Spark支持多种Join形式:
- Inner Join 内连接, 取相同的部分
- Left Join 左连接, 左表为主
- Right Join 右连接
- Anti Join 剔除可以和右表Join上的左表部分. 相当于not in.
- Semi Join 相当于In
到目前为止, 数据关联总共有3中Join的实现方式, 分别是:
- 嵌套循环连接(NLJ, Nested Loop Join)
- 排序归并连接(SMJ, Shuffle Sort Merge Join)
- 哈希连接(HJ, Hash Join)
NLJ的工作原理:
使用两层循环, 将体量较大的表做外层循环, 体量较小的表做内层循环
NLJ的计算复杂度为O(M*N).
SMJ的工作原理
SMJ的思路是先排序, 再归并. 两张表先根据Join Key做排序, 然后使用两个游标对排好序的表进行归并关联.
SMJ的计算复杂度为O(M+N), 但是这个是依赖与排好序的基础上.
HJ的工作原理
将内表扫描的复杂度降至O(1).
首先将内表基于既定的哈希函数构建哈希表, 然后外表扫描时使用相同的哈希函数去哈希表中查找.
所以总体的复杂度为O(M)
分布式环境下的Join
分布式环境中的数据关联在计算环境依然遵循着NLJ, SMJ和HJ这三种实现方式, 只不过是增加了网络分发这一变数.
在Spark的分布式计算环境中, 数据在网络中的分发主要有两种形式, 分别是Shuffle和广播.
如果使用Shuffle的方式来完成分发, 那么外表和内表都需要按照Join Key在集群中做全量的数据分发.
如果采用广播机制的话, Spark只需要将内表封装到广播变量, 然后在全网进行分发.
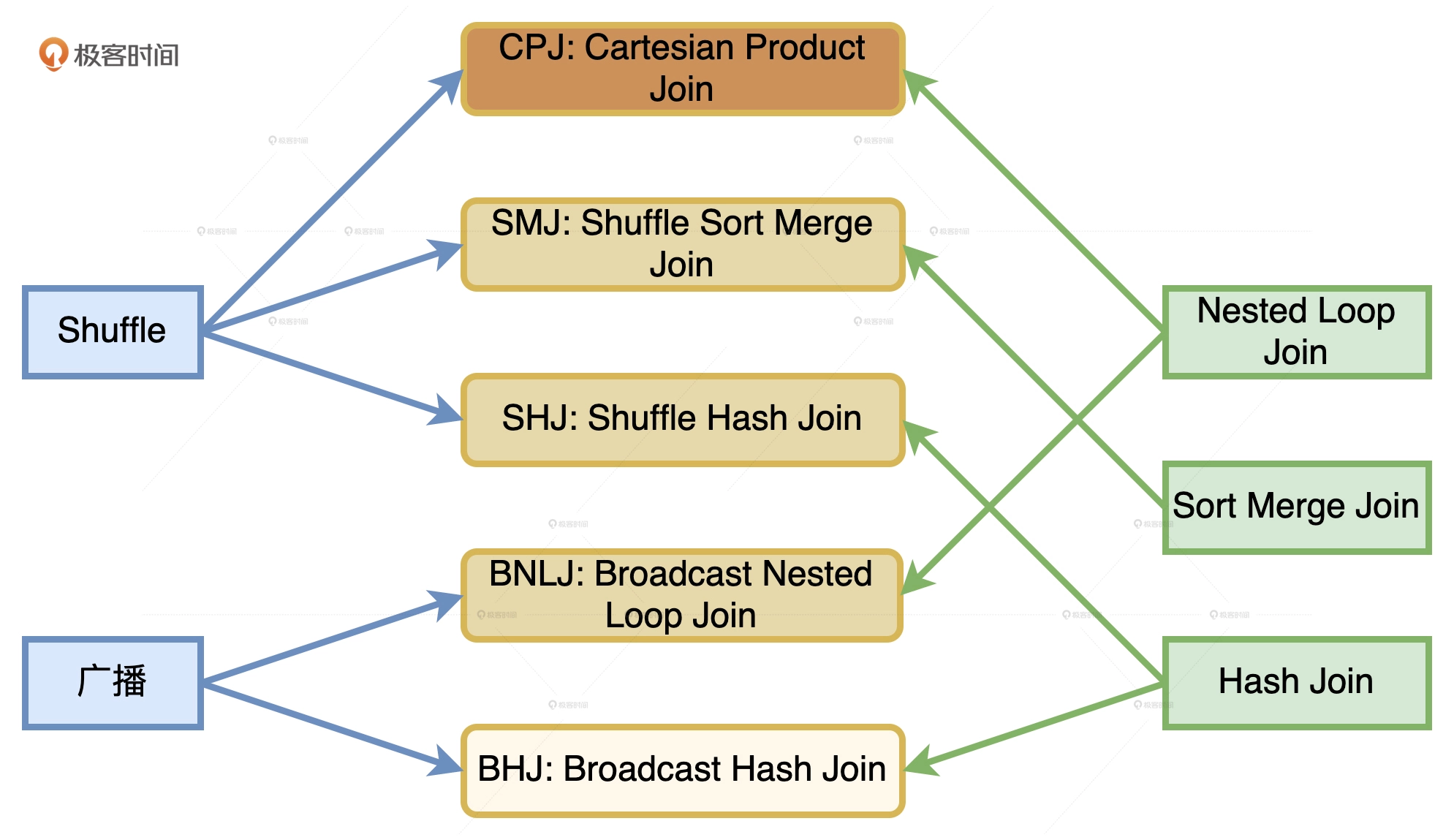
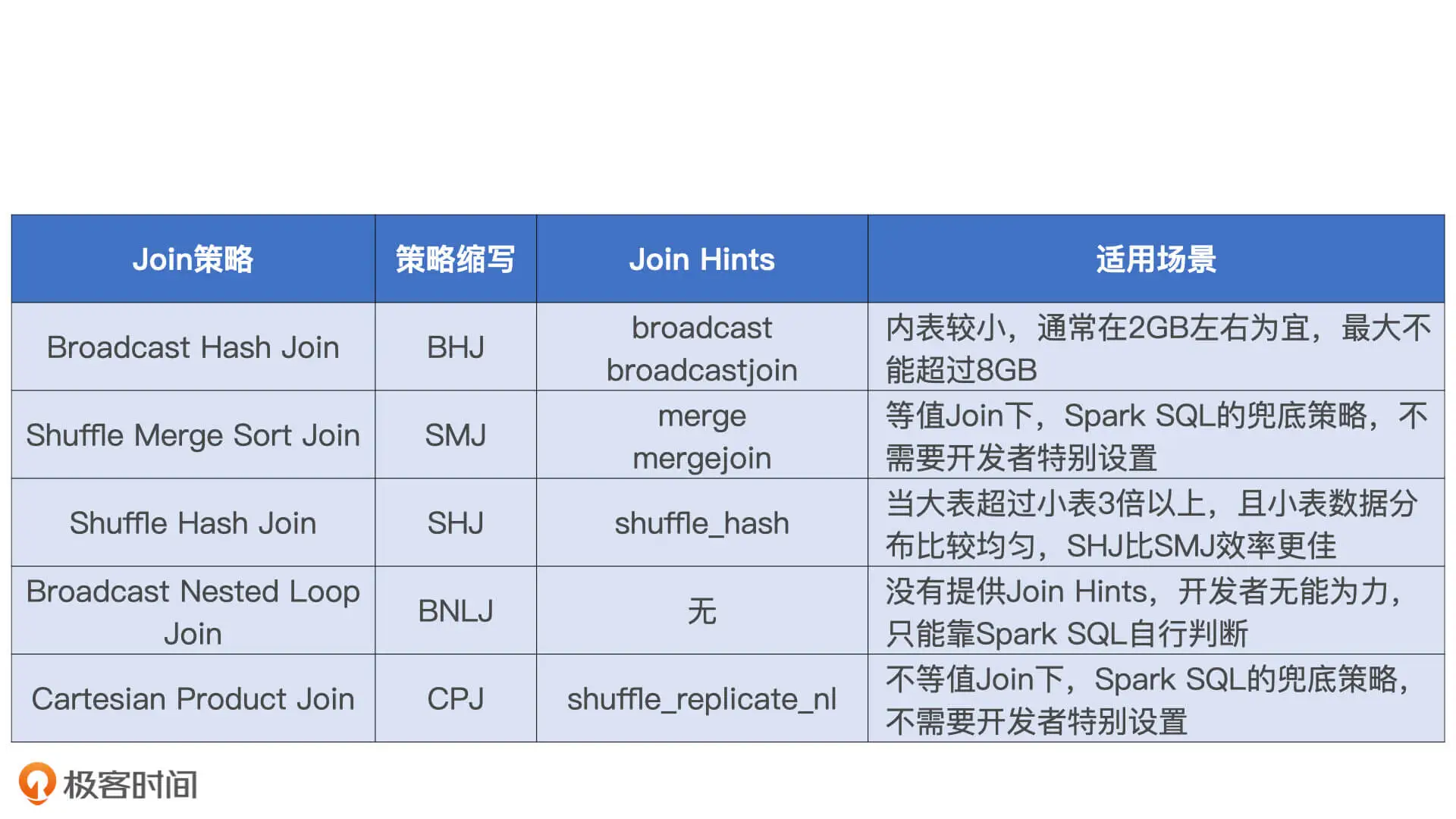
结合Shuffle、广播这两种网络分发形式和NLJ, SMJ, HJ这三种计算方式, 对于分布式环境下的数据关联, 组合起来可以有6种Join策略, 分别是:
-
CPJ: Cartesian Product Join
-
SMJ: Shuffle Sort Merge Join
支持所有的连接类型
-
SHJ: Shuffle Hash Join
支持所有的连接类型
- 外表大小至少是内表的3倍
- 内表数据分片的平均大小要小于广播变量阈值
- 参数spark.sql.join.preferSortMergeJoin=false
-
BNLJ: Broadcast Nested Loop Join
-
BHJ: Broadcast Hash Join
- 连接类型不能是全连接(full outer join)
- 小表要能够放到广播变量里
从执行性能上, 5中策略从上到下由弱变强.
相比SMJ, HJ不要求参与Join的两张表有序, 只要小表可以放进内存, 就可以在遍历大表时完成关联计算.
Spark如何选择Join策略
等值Join
按照 BHJ > SMJ > SHJ 的顺序依次选择Join策略
BHJ效率最高, 但是需要满足两个条件
- 连接类型不能是全连接
- 小表足够小, 能够放到广播变量里
SHJ尽管效率比SMJ高, 但是不稳定, 原因是:
SHJ需要将两个表都根据Join Key进行重分区, 然后将两个表的相同key分发到相同executor上, 但是这里不能保证小表足够小, 有可能是两个大表, 从而造成OOM.
而SMJ没有这么多附加条件, 它可以借助磁盘来完成排序和存储.
所以Spark会优先选择SMJ而不是SHJ.
并且如果在spark.sql.join.preferSortMergeJoin=true(默认为true)的情况下, Spark也不会去尝试SHJ.
不等值Join
不等值Join只能使用NLJ来实现, 因此Spark SQL可以选的策略只剩下BNLJ和CPJ. 选择顺序为BNLJ > CPJ.
BNLJ的前提是内表足够小, 可以放到广播变量中, 否则只能去选择CPJ.