数据存储格式
首先是分区目录,这个与Hive上的分区表一致。
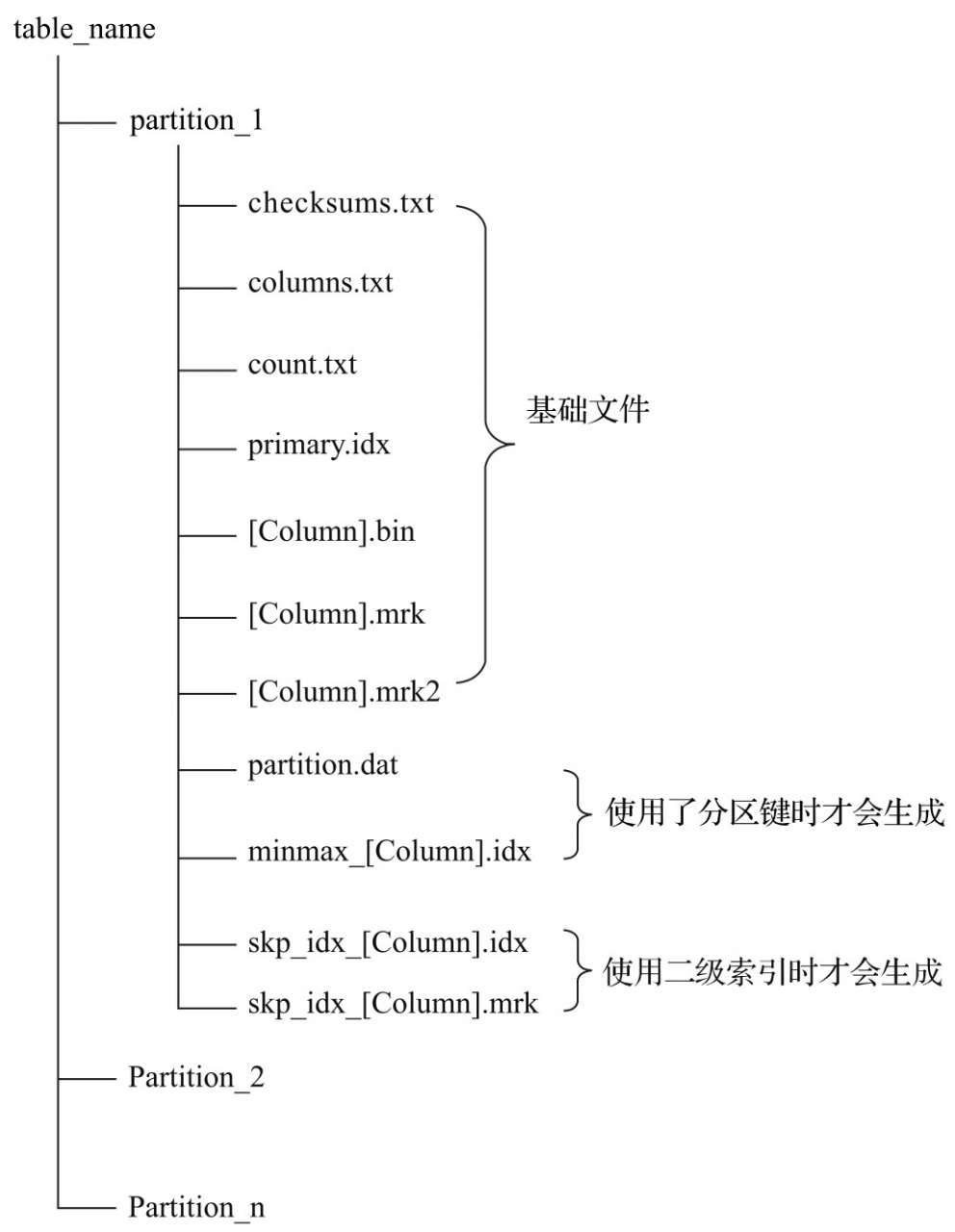
一些基础文件:checksum.txt是校验文件,count.txt明文记录了这个分区下数据量,columns.txt明文记录了这个表的schema结构
然后是数据文件,ClickHouse采用了列式存储,而且是每一列都会有单独的文件,比如一个表有id,name两列,就会有id.bin, name.bin数据文件,mrk(mrk2) 列字段标记文件,存储了bin文件中数据的偏移量信息,使用二进制格式存储。
primary.idx索引文件,记录了索引与mrk2文件直接的关系,索引在内存也保存了一份,查询时不会使用磁盘上的文件(重启时需要加载到内存中)
分区规则
ClickHouse支持分区,但是与Hive中的分区有所不同。
对于不同的分区字段有不同的规则:
- 没有设置分区
- 这个时候所有数据存到一个文件夹下,文件名称为
all
- 这个时候所有数据存到一个文件夹下,文件名称为
- 分区为数字类型
- 分区文件夹为数字
- 分区为时间类型
- 文件夹为
yyyyMMdd格式
- 文件夹为
- 分区为其他类型(比如字符串)
- 对值做哈希后,作为文件夹名称
分区命名规则
***PartitionId_MinBlockNum_MaxBlockNum_Level***
文件夹总体的名称分为4部分
- PartitionId是根据字段真实值与上面的规则生成。
- Level:这个文件夹被merge的的次数
- BlockNum: 在一个表中这个值从1开始累加,每次新生成一个文件夹,这个文件夹的MinBlockNum和MaxBlockNum是相同的值(比如说1),然后这个值加1,第二次生成的文件夹MinBlockNum和MaxBlockNum变成了2,在后续的Merge过程中,两个文件夹merge时,会取两个文件夹中的最小和最大值来作为新文件夹的MinBlockNum和MaxBlockNum。
数据写入过程
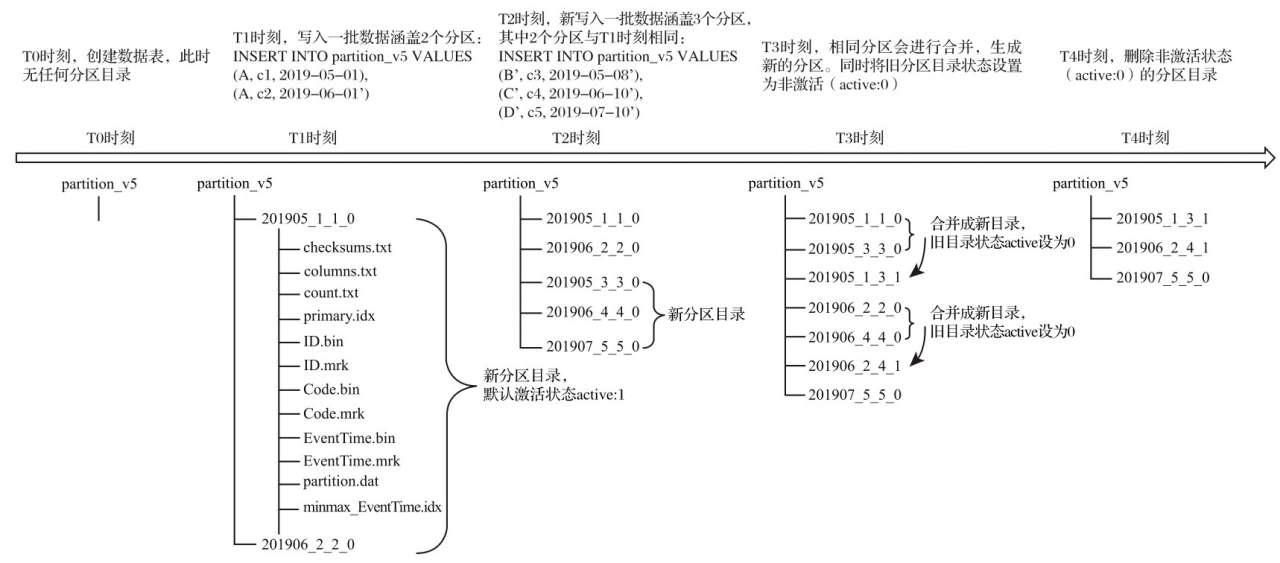
来解释一下上面这个图
首先是表的定义,被写入的这个表定义了一个按月分区的分区规则 partition by toYYYYMM(dt)。
- T1时刻,写入了两条数据,两条数据的月份不一致(5月,6月),所以会写到两个分区文件夹下
- T2时刻,写入了三条数据。这三条数据中,两条分别与上一次T1时刻插入的月份一致(5月,6月),还有一条与之前不一致(7月)。这个时候与之前相同月份的数据还会新创建一个文件夹来保存数据,并不会合并到之前已经创建的分区文件夹中。
- T3时刻,这个时候后台会将相同时间的文件夹进行合并,这个时候我们有5个文件夹,里面有2个5月,2个6月,1个7月。合并时分区文件夹的命名会进行改变。最后面的level表示这个文件夹被merge的次数,BlockNum会取被merge的两个文件夹中最大最小值。
数据文件的写入过程
刚刚是数据文件夹的写入过程,让我们从文件夹进入到文件,看一下里面的这些文件是如何生成的。
ClickHouse中数据是按列来进行存储的,并且是每一列都有单独的.bin文件.
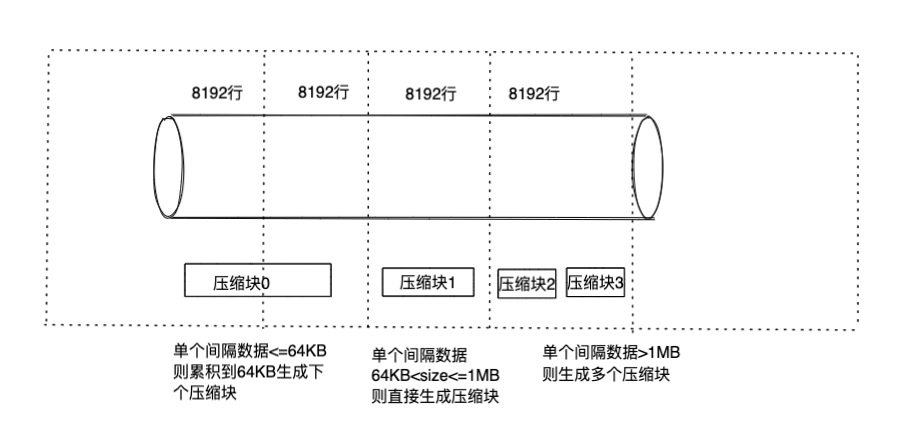
在bin文件夹中数据是经过压缩后进行存储的,数据压缩不是将全部的数据进行整体压缩,而是将数据分块,对每一块进行单独的压缩。
每一个压缩块的大小在64KB到1MB之间
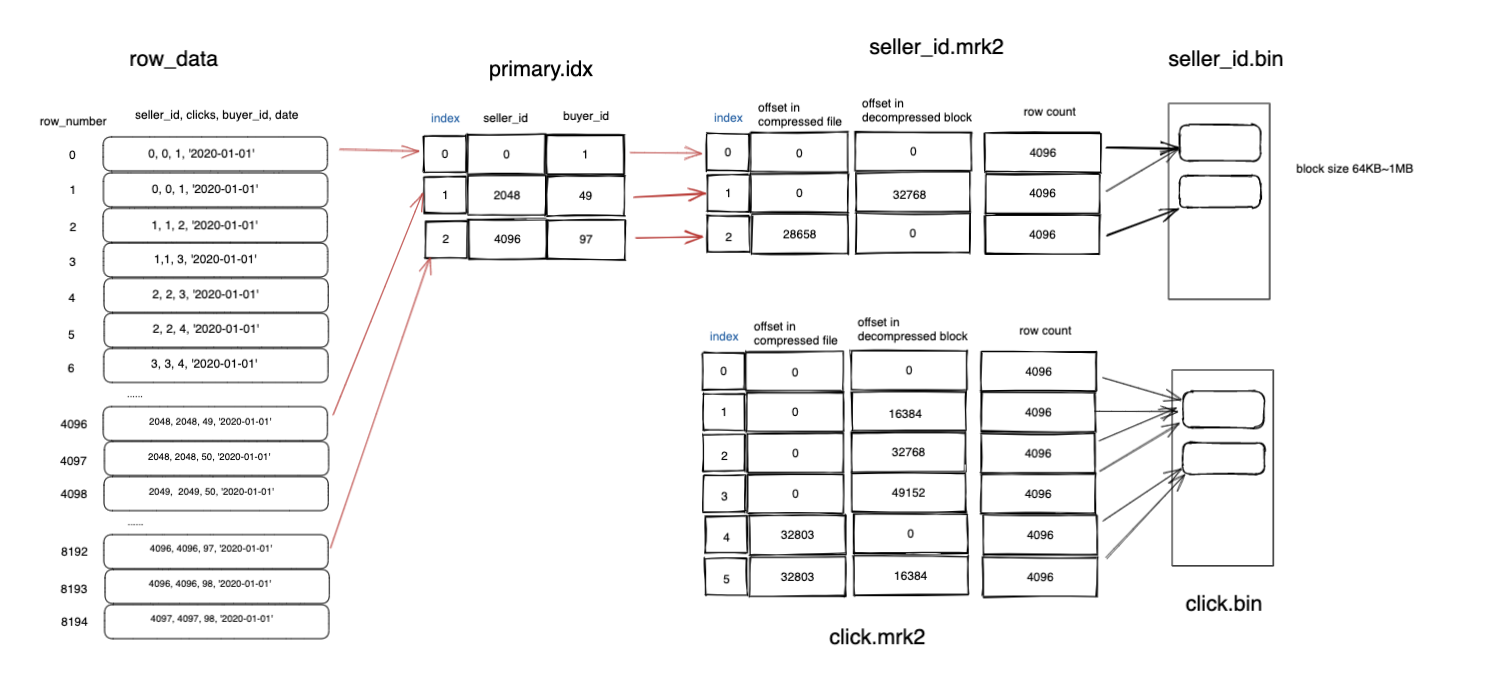
用这样的一个图来说明一下索引文件(primary.idx),数据标记文件(mrk2),数据文件直接的关系(bin)
表的定义:
|
|
我将这个表的索引粒度修改为4096,意味着4096条记录会作为一个单位来进行存储。
数据按照order by的字段来进行排序,然后按照索引粒度来生成索引文件,每4096行会生成一条索引,然后将这些记录压缩后写入到bin文件中,最后在mrk2文件中记录索引与bin文件直接的关系。
以上面的数据为例,0~4096条的大小不满足64KB,所以需要与40968192条一起放到一个压缩块中,那么在mrk2文件中,04096与4096~8192这两个在bin文件中的压缩文件位置是一样的,但是在解压缩后的位置是不一样的。
clicks这个字段也会按照相同的规则来生成文件夹和mrk2文件,这样当我们需要走索引查询时可以很容易的找到相应的值。而且每次拿出来的最小块是在1MB左右,与HDFS默认128MB相差了128倍。
延伸
- 从这个写入过程可以看出来,ClickHouse数据写入是直接写入到磁盘中,中间没有做内存的缓存,所以如果一批数据在中间出错就会出现问题。- 不能保证原子性
- 同样,在数据写入时也不会去校验
primary key的唯一性,在之前的数据库中我们认为pk是唯一的,但是在ClickHouse中定义的primary key并不是唯一的,可以存在多个值。- 与传统数据库区别 - 当插入批次过多,或者每次插入数据量很小时,会对ClickHouse造成很大的压力,有可能会后台merge不过来从而报错,所以在真实业务中可以对插入进行缓存,将streaming变成mini batch - 业务使用建议
其他MergeTree引擎
这些引擎都是在相同分区的文件夹Merge过程中,增加了一些操作。