前言
这篇文章记录一下ClickHouse的几种原生引擎的数据写入过程
MergeTree
MergeTree是ClickHouse的最基础引擎,其它引擎都是基于这个引擎来进行扩展的,所以先来看一下这个引擎的写入过程。
先看一下要创建这个引擎的DDL语句:
|
|
首先 ENGINE = MergeTree()表明这个表的引擎
- [ON CLUSTER cluster] 添加这一句可以在集群名为cluster的集群上创建这张表,而不需要去每个节点都创建一遍
- ORDER BY expr 声明主键,ClickHouse的主键是可以重复的。数据存储会按照这个进行排序
- PARTITION BY 分区字段,不同的数据会存储在不同的文件夹下
- PRIMARY KEY expr 设置主键,一般情况下使用ORDER BY来完成,如果同时出现ORDER BY与PRIMARY KEY,primary key需要是order by的子集
数据存储
ClickHouse的数据存储位置由配置文件config.xml中指定,默认路径为/var/clickhouse/data/
在这个路径下首先按照数据库名称,表名称进行区分。在一个表下的又会存在多个分区文件夹。
分区文件夹命名规则
分区文件夹的名称格式长这样:
PartitionId_MinBlockNum_MaxBlockNum_Level
PartitionId
-
None
当未指定分区字段时,会生成一个
all的文件夹,所有数据都在这个文件夹下 -
Number
当分区字段为数字时,会使用数字作为文件夹的名称
-
Date
当分区字段为日期时,将会格式化为yyyyMMdd格式
-
Others
其它情况会将分区值做一次哈希,然后使用哈希值作为文件夹名称
BlockNum
ClickHouse会在每个表上维护一个全局递增的数字,每创建一个文件夹都会更新这个数字,新创建文件夹的Min和Max都是相同的数字,在后续merge的过程中,会取两个文件夹block num的最大最小值作为新文件夹的min,max。
Level
表示这个文件夹被merge的次数,每被merge一次,这个数字都会加1.
举个🌰:

每个文件夹是否是active的状态则被保存在system.parts表中
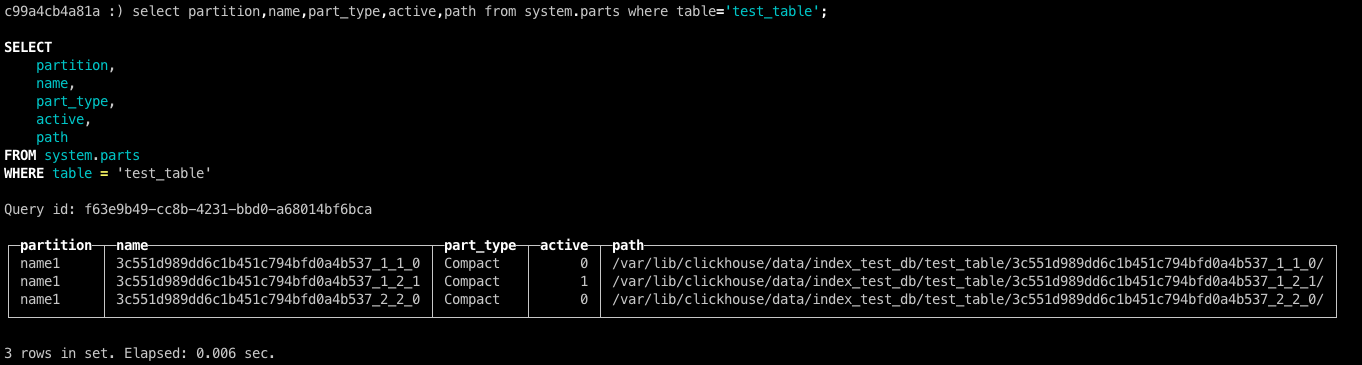
数据存储结构
看完外层文件夹被合并的过程,再看一下文件夹内部的文件存储

在单个文件夹内主要包含这几个文件:
-
primary.idx
主键索引
-
[Column].mrk2
-
[Column].bin
由于ClickHouse采用了列式存储,所以每一列都会有mrk2, bin两个文件
bin文件是存储的被压缩过的真实数据文件,mrk2文件中保存了主键索引与文件块之间的关系
-
count.txt
-
columnar.txt
这两个文件都是明文存储的,分别保存了在这个文件夹下的记录数量以及表结构
每次写入都会生成这些文件,即便是一次一条记录,所以clickhouse的写入最好还是批量写,在实时场景下做一下缓存后再进行写入。不然每次都会产生这些文件,造成大量的IO操作,后续也需要大量的merge过程,并且在查询时也会有一定的影响,对查询的影响在查询的部分再进行细说。
由于clickhouse在每次插入时数据都是直接落盘的,不会有log或者内存缓存再写入的过程。从这一地方也可以看出不支持事务。
在数据写入时不会进行一遍主键校验,所以主键是会重复的。为了解决这个文件,clickhouse有一个ReplacingMergeTree引擎来实现主键去重,但也只是一定程度上解决了主键重复。
其他的若干种引擎,都是基于MergeTree引擎的合并过程做了一些修改,扩展。
ReplacingMergeTree
可以在一定程度上解决主键重复的问题,异步完成的,有一定的时间延迟。
例如我们的DDL以及几条数据如下:
|
|
id name age
1 name1 18
1 name2 18
2 name3 19
这3条数据分3批进行插入,3条数据都完成写入后,文件夹及数据长这样
文件夹:
- 18_1_1_0
- 18_2_2_0
- 19_3_3_0
数据:
id name age
1 name1 18
1 name2 18
2 name3 19
这不是跟之前一样吗,并没有数据去重。
是的,在数据刚刚写入的时候数据确实是这样的,数据去重发生在文件夹merge的过程中。
我们可以手动执行命令来触发文件夹合并optimize table db_name.table_name,或者等待几分钟后clickhouse也会自动执行merge过程。
在文件夹合并之后的文件夹及数据是这样:
-
文件夹
- 18_1_2_1
- 19_3_3_0
-
数据
id name age
1 name1 18
2 name3 19
这个时候在相同分区下的主键重复数据就被删掉了一条。这里需要注意的是,如果主键分布在不同的分区下,那么相同主键的数据是不会被删除的(因为它们不会被merge到一个文件夹下)。所以使用这个引擎并不能保证数据的唯一性,只能在一定情况下保证数据的唯一性。