定义
在生产环境下, 对于大表经常需要对其分表, 将数据分别存储在不同的节点上. ClickHouse的Distribbuted表引擎做的就是这件事情.
ClickHouse中的分布式表并不存储数据, 只是做请求和写入的转发, 类似view的概念.
如何定义:
1 | CREATE TABLE table_all ON CLUSTER clusterName ( |
在定义时支持sharding_key的定义, 这样我们可以自定义数据的分布, 但是这个值必须是数值型, 可以自己是一个数值型字段, 也可以是某个函数的结果
支持的分片策略:
None
只能写入一个分片, 如果这个集群存在多个分区就会报错.
rand()
随机写入, 默认是轮循.
数值型字段
hash(字段)
或者业务方, 自己对数据进行切片后, 将数据写入到对应节点的本地表中. 不通过ClickHouse进行分发.
数据分发过程
由于ClickHouse是多主架构, 所以数据可以被写入任意节点. ClickHouse会在内部自己进行数据的分片划分.
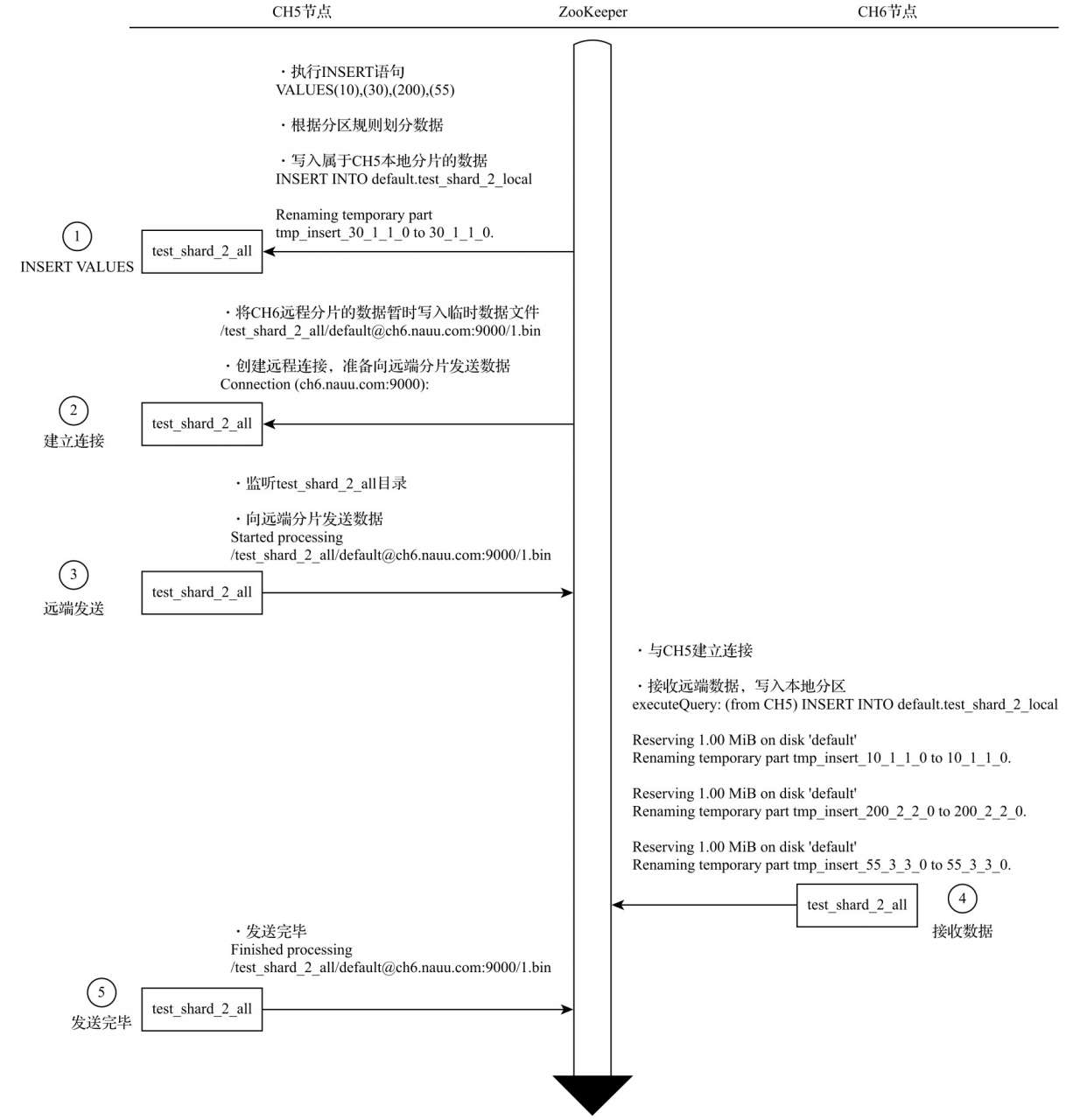
从上图可以看出, ClickHouse内部进行了二次的数据分发, 不属于自己节点的数据会有两次的网络传输, 所以有很多时候使用方会进行自己对数据进行切分, 将数据写入到对应节点的本地表上. 从而提高性能.