Map阶段的输出是什么
Map阶段最终生成的数据会以中间文件的形式物化到磁盘中, 这些文件存储在spark.local.dir设置的文件目录中. 中间文件包含两种类型:
后缀为data的数据文件
存储的内容是Map阶段生成的待分发数据
后缀为index的索引文件
记录的是数据文件中不同分区(Reduce阶段的分区)的偏移地址. 分区数量与Reduce阶段的并行度保持一致.
Map阶段的每个Task都会生成这样的一组文件, 因此中间文件的数量与Map阶段的并行度保持一致.
数据生成过程
计算目标分区
在Spark中, 每条数据的分区是由Key的哈希值决定的
写入缓存区或溢写到文件
GroupByKey的实现
计算完目标分区后, Map Task会把每条记录和它的目标分区, 放到一个特殊的数据结构PartitionedPairBuffer里, 这个数据结构本质上是一个数组形式的缓存结构.
每条数据都会占用数组中相邻的两个元素空间, 第一个元素存储(目标分区, Key), 第二个元素存储值.
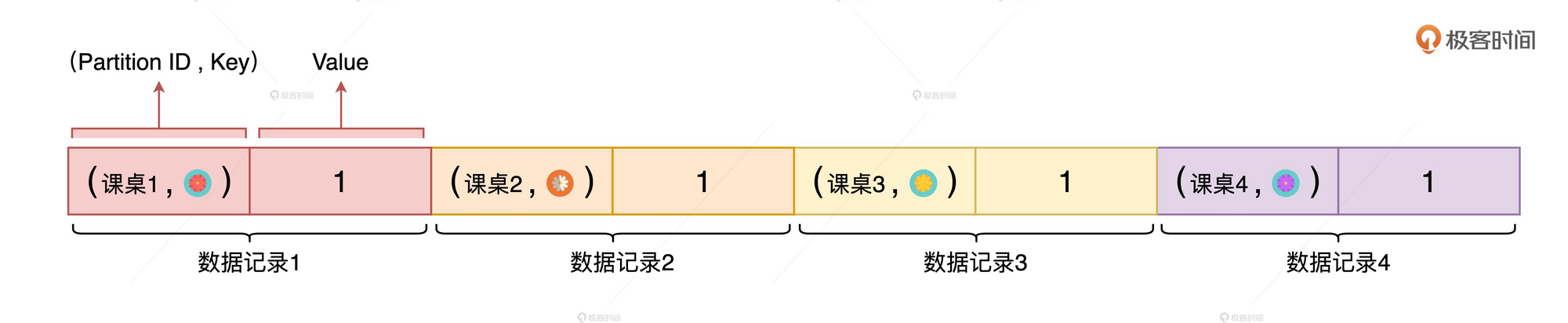
这个数组的长度不可能无限大来存储所有Map端的元素. 所以Spark有一种机制, 来保障在数据总量超过可用内存的情况下, 依然能够完成计算. 这种机制就是: 排序、溢出、归并.
举个例子:
假如我们的PartitionedPairBuffer 的数组长度为8, 也就是说可以存储4个元素. 而我们的Map端共有16个元素, 那么就会需要4批才能完成计算. 在处理第二批的数据时, Spark会将第一批的数据溢写到磁盘的临时文件上.
在溢写时, 会对PartitionedPairBuffer 中已有的数据, 按照目标分区以及Key进行排序后再进行写入, 所以临时文件中的数据是有序的.
在处理第四批的时, 这时已经是最后一批, 所以这次不再需要溢写到临时文件. 现在的数据分布在3个临时文件中, 还有缓存在PartitionedPairBuffer中.
最后, 会从这两个输入源中(临时文件, 缓存区)生成最终的数据文件和索引文件. 并且由于每个文件都是有序的, 所以在合并时使用了归并算法.
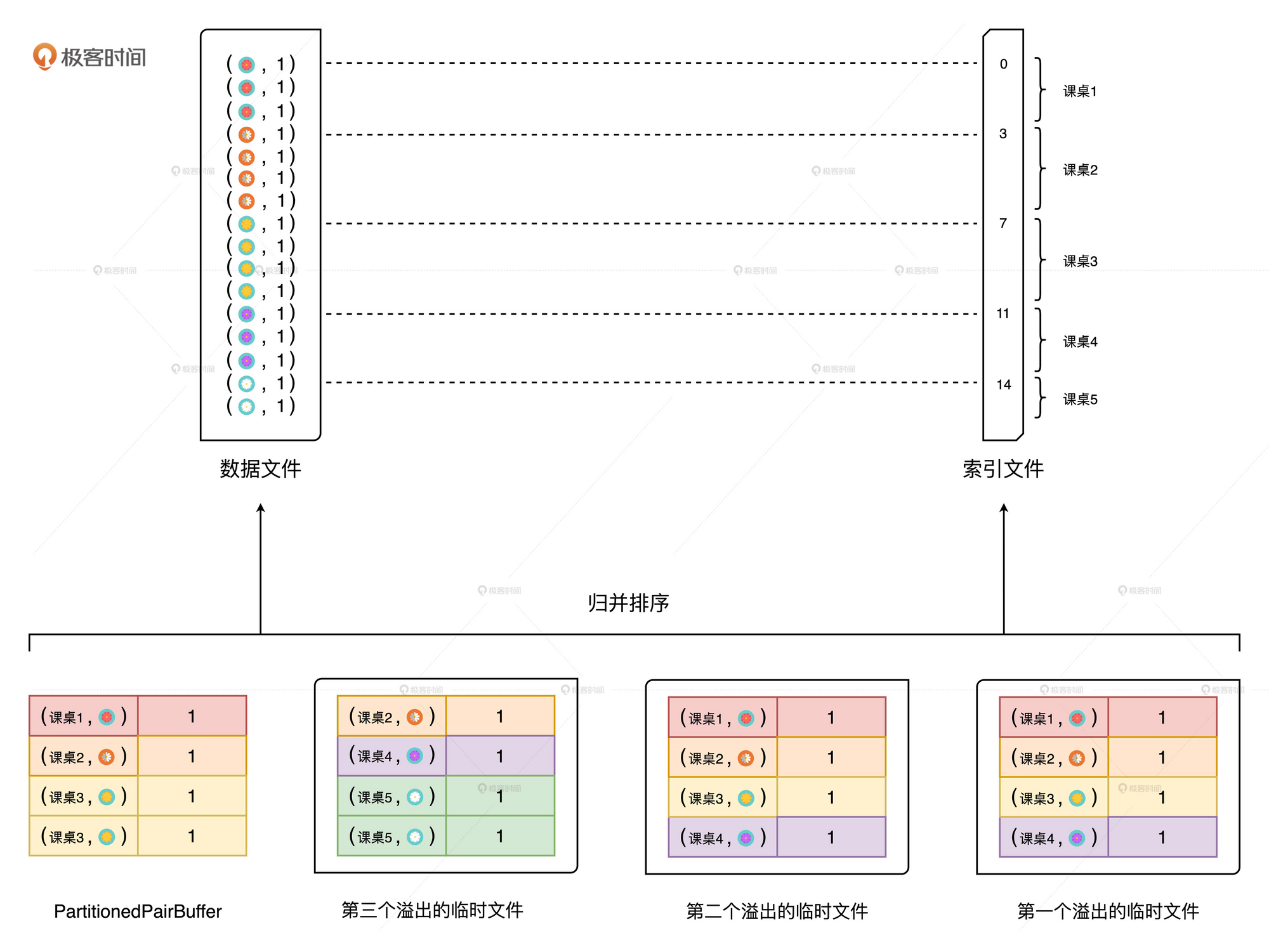
主要步骤为:
- 对于分片中的数据记录, 逐一计算其目标分区, 并将其填充到PartitionedPairBuffer
PartitionedPairBuffer填满后, 如果后续还有未处理的数据, 则对Buffer中的数据按(Partition ID, Key)进行排序, 将Buffer中的文件溢出到临时文件, 同时清空缓存区- 重复步骤1, 2. 直到分片内的所有数据都被处理
- 对所有临时文件和
PartitionedPairBuffer归并排序, 最终生成数据文件和索引文件
ReduceByKey
ReduceByKey的计算步骤与GroupByKey的一样, 都是先填充内存数据结构, 然后排序溢出, 最后归并排序.
不一样的地方是, ReduceByKey采用了一种PartitionedAppendOnlyMap 的数据结构来填充数据记录, 这个数据结构是一种Map, 而Map的值是可以累加, 可以更新的. 所以非常适合用于聚合类的计算场景, 如计数、求和、均值计算、极值计算等.
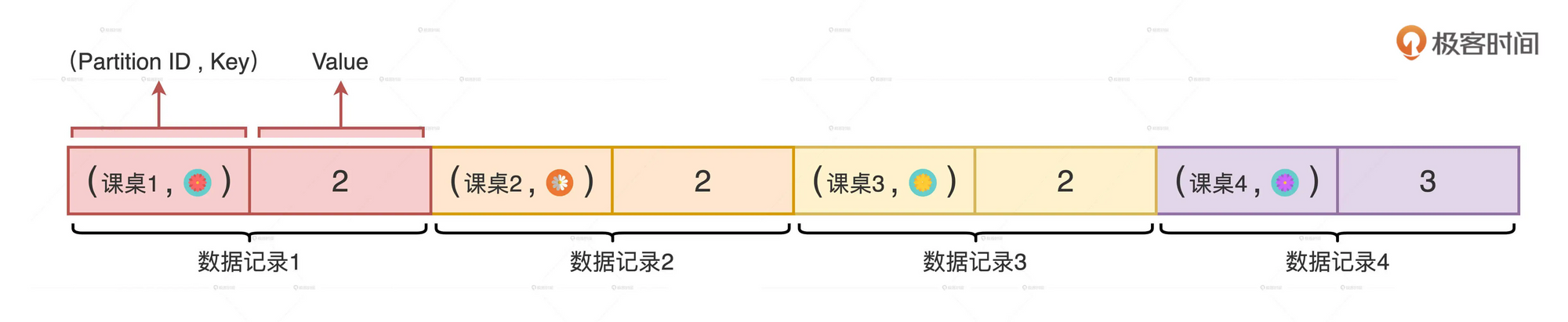
相比PartitionedPairBuffer, PartitionedAppendOnlyMap的存储效率要高很多, 溢出数据到磁盘文件的频率也要低很多. 因此最终合并的数据文件也会小很多.
依靠高效的内存存储结构、更少的磁盘文件、更小的文件尺寸. 大幅降低来Shuffle过程中的磁盘和网络开销.
Reduce阶段流程

Reduce阶段需要主动从Map端中间文件中拉取数据.
每个Map Task都会生成上图这样的文件, 文件中的分区数与Reduce阶段的并行度一致. 也就是说每个Map Task生成的数据文件, 都包含所有Reduce Task所需的部分数据.
因此, 任何一个Reduce Task都需要从所有的Map Task拉取属于自己的那部分数据. 索引文件用于帮助判定哪部分数据属于哪个Reduce Task.
Reduce Task通过网络拉取中间文件的过程, 实际上就是不同Stages之间数据分发的过程.
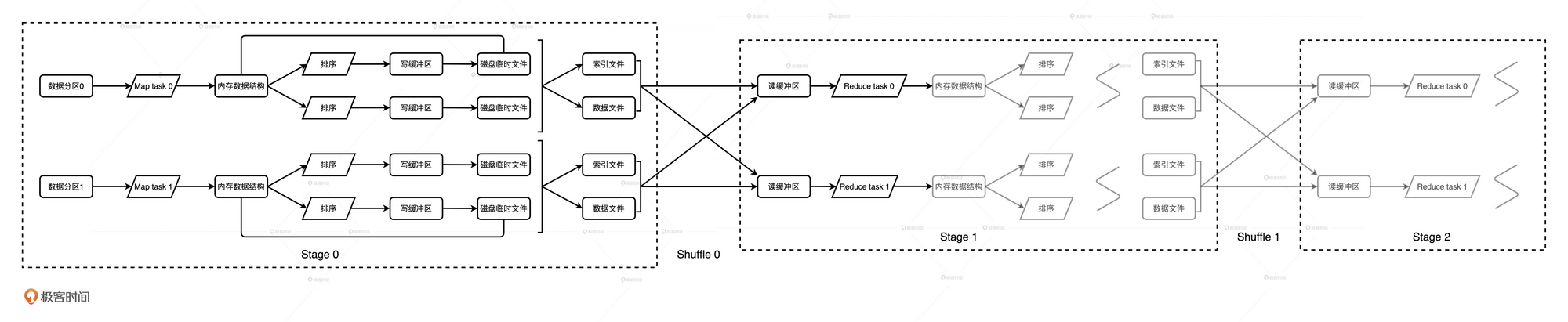
Reduce Task将拉取到的数据块填充到读缓存区, 然后按照任务的计算逻辑不停的消费、处理缓存区中的数据记录.
总结
对于Shuffle, 它需要消耗所有的硬件资源
- 无论是PartitionedPairBuffer、PartitionedAppendOnlyMap这些内存数据结构, 还是读写缓冲区, 都需要消耗内存资源
- 由于内存空间有限, 因此溢写的临时文件会引入大量的磁盘I/O, 而且Map阶段输出的中间文件也会消耗磁盘
- Reduce阶段的数据拉取, 需要消耗网络I/O.
其次, 消耗的不同硬件资源之间很难达到平衡.