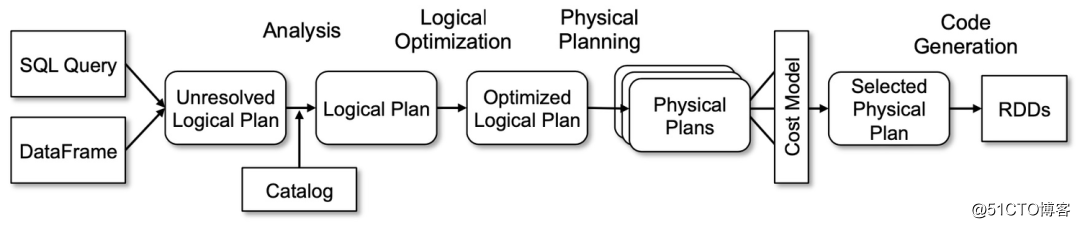
Spark SQL完整优化流程主要包含两个阶段: Catalyst优化器和Tungsten. 其中Catalyst优化器包含逻辑优化和物理优化两个阶段.
1 | select name, age, sum(price * volume) revenue |
ANTLR4
在编写完SQL或DataFrame后, spark会先使用Antlr来生成逻辑计划树Unresolved Logical Plan
Catalyst
Catalyst逻辑优化阶段分为两个环节: 逻辑计划解析和逻辑计划优化.
在逻辑计划解析中, Catalyst把Unresolved Logical Plan转换为Analyzed Logical Plan;
在逻辑计划优化中, Catalyst基于一些既定的启发式规则(Heuristics Based Rules)把Analyzed Logical Plan转换为Optimized Logical Plan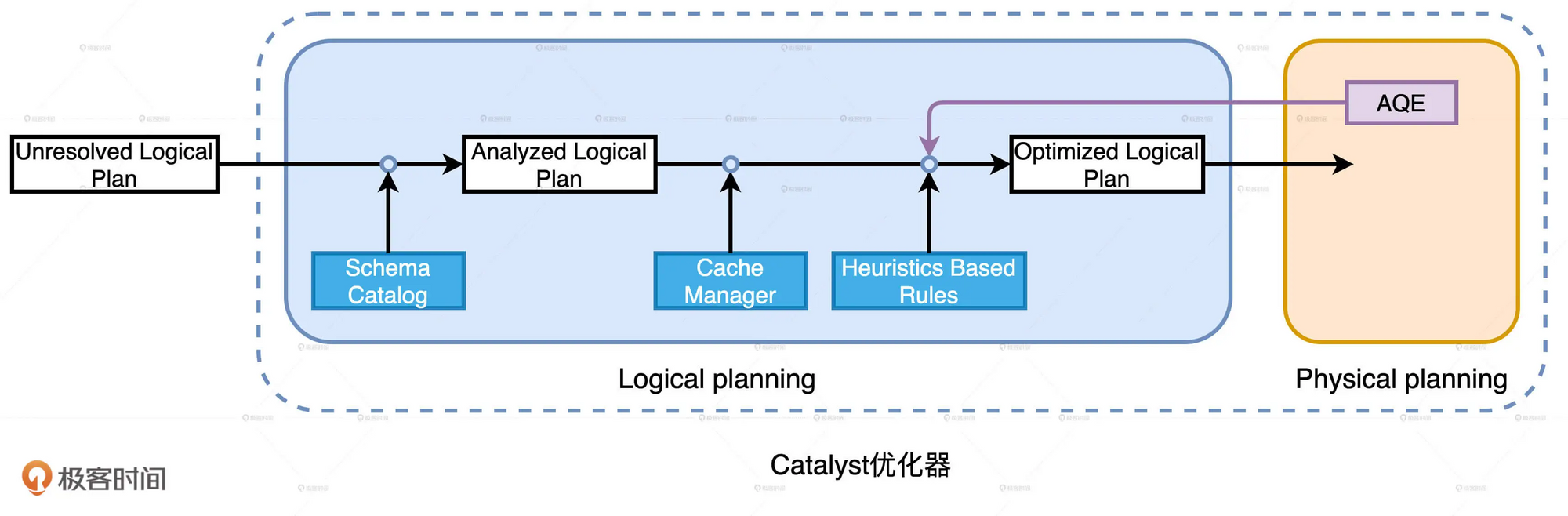
逻辑计划解析
这一步是把Unresolved Logical Plan转换为Analyzed Logical Plan
要结合DataFrame的Schema信息, 来确认计划中的表名, 字段名, 字段类型与实际数据是否一致. 如果我们的查询中存在表名, 列名不存在. 会在这一步报错.
完成确认后, Catalyst会生成Analyzed Logical Plan.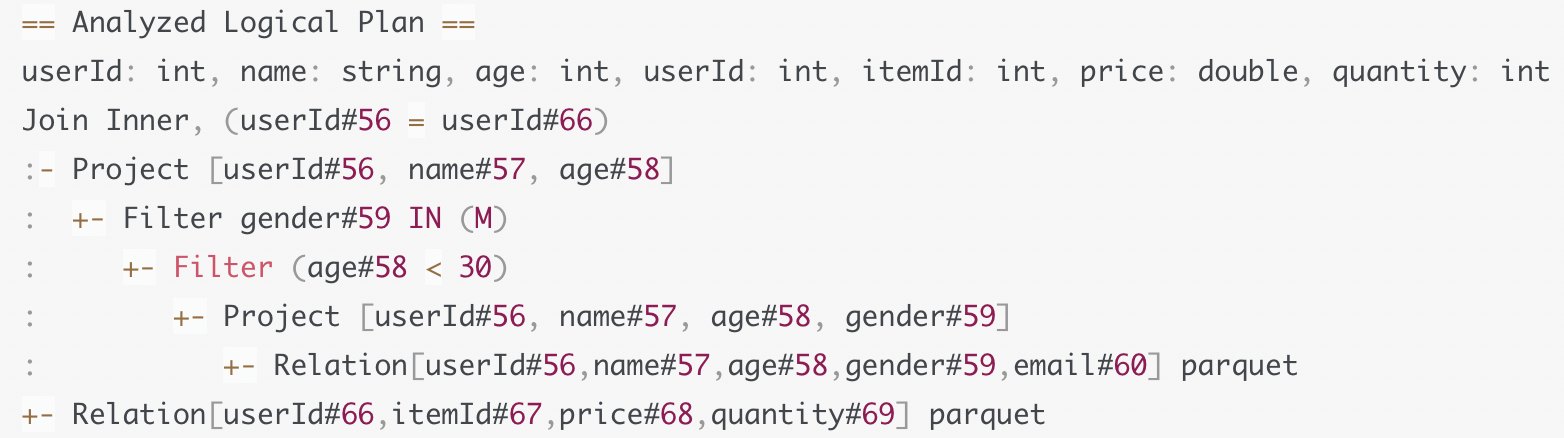
逻辑计划优化
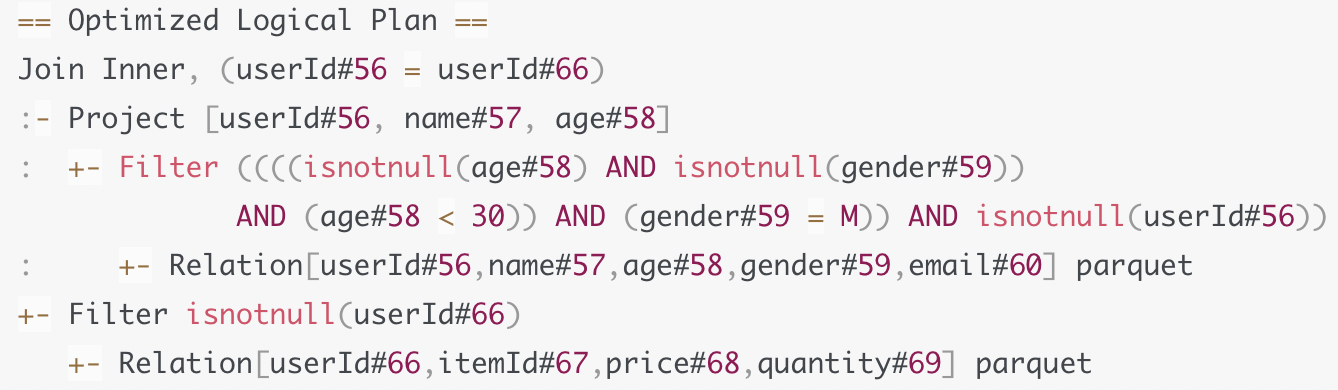
这一步将Analyzed Logical Plan转换成Optimized Logical Plan
在解析完逻辑计划之后, 我们也可以直接将Analyzed Logical Plan转换为物理计划. 但是这个时候的执行效率可能不是最优的, 我们根据一系列既有规则进行优化, 优化后再转换为物理计划.
例如上面的Analyzed Logical Plan, 我们在查询中只涉及到user表的4个字段, 但是由于parquet文件中存在5个字段. 我们其实可以将没有用到的email字段舍弃掉.
对于同样一种计算逻辑, 实现方式可以有多种, 按照不同的顺序对算子做排列组合, 我们可以演化出不同的实现方式. 需要去选择其中最优的哪一个.
Catalyst的优化规则
优化规则主要可以归纳到3个范畴:
- 谓词下推 (Predicate Pushdown)
- 列剪裁 (Column Pruning)
- 常量替换 (Constant Folding)
- 谓词下推
谓词指的是一些过滤条件比如age<30, 下推指的是把这些谓词沿着执行计划向下, 推到离数据源最近的地方, 从而在源头就减少数据扫描量. 让这些谓词越接近数据源越好
在下推之前, Catalyst还会对谓词本身做一些优化, 比如像OptimizeIn规则, 它会把gender in ‘M‘ 优化为 gender = ‘M’ , 把谓词in替换为等值谓词. 再比如CombineFilters规则, 它会把age<30 和 gender=’M’ 这两个谓词, 捏合成一个谓词: age≠null and gender ≠null and age < 30 and gender = ‘M’
完成谓词本身的优化之后, Catalyst再用PushDownPredicte优化规则, 把谓词推到逻辑计划树的最下面的数据源上. 下推的谓词能够大幅减少数据扫描量, 降低磁盘IO
2. 列剪裁
扫描数据源时, 只读取那些与查询相关的字段.
在上面的例子中, 对于email字段, 虽然在数据中存在, 但是并没有查询这个字段, 所以Catalyst会使用ColumnPruning规则, 把email字段这一列剪掉. 对于列式存储的文件可以减少文件扫描数量, 降低IO开销.
- 常量替换
对于我们的一些常量表达式, 例如 age < 12+ 18. 会使用ConstantFolding规则, 自动帮我们把条件变成 age<30
Catalyst的优化过程
逻辑计划(Logical Plan)和物理计划(Physical Plan),它们都继承自 QueryPlan。
QueryPlan 的父类是 TreeNode,TreeNode 就是语法树中对于节点的抽象。TreeNode 有一个名叫 children 的字段,类型是 Seq[TreeNode],利用 TreeNode 类型,Catalyst 可以很容易地构建一个树结构。除了 children 字段,TreeNode 还定义了很多高阶函数,其中最值得关注的是一个叫做 transformDown 的方法。transformDown 的形参,正是 Catalyst 定义的各种优化规则,方法的返回类型还是 TreeNode。另外,transformDown 是个递归函数,参数的优化规则会先作用(Apply)于当前节点,然后依次作用到 children 中的子节点,直到整棵树的叶子节点。
从Analyzed Logical Plan到Optimized Logical Plan的转换,就是从一个 TreeNode 生成另一个 TreeNode 的过程
Analyzed Logical Plan 的根节点,通过调用 transformDown 方法,不停地把各种优化规则作用到整棵树,直到把所有 27 组规则尝试完毕,且树结构不再发生变化为止。这个时候,生成的 TreeNode 就是 Optimized Logical Plan。
物理计划
优化Spark Plan
上面得到的Optimized Logical Plan 只是一些逻辑计划, 不具备可操作性.
例如下面这个计划, 只是声明了join的方式为inner join. 但是并没有说明我们是需要boradcast join, 还是sort merge join或者其他join方式.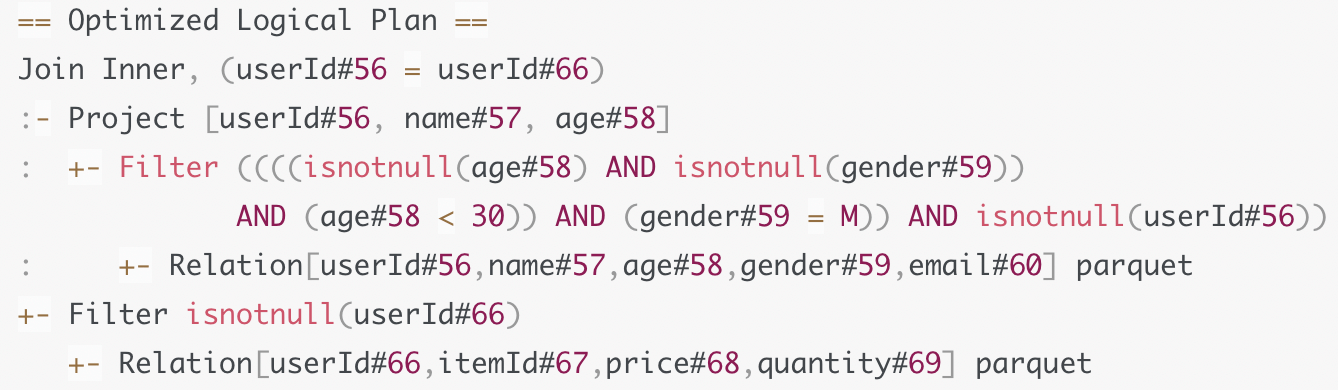
在这一步中, Catalyst共有14类优化策略, 其中6类与流计算相关, 剩下的8类使用与所有的场景.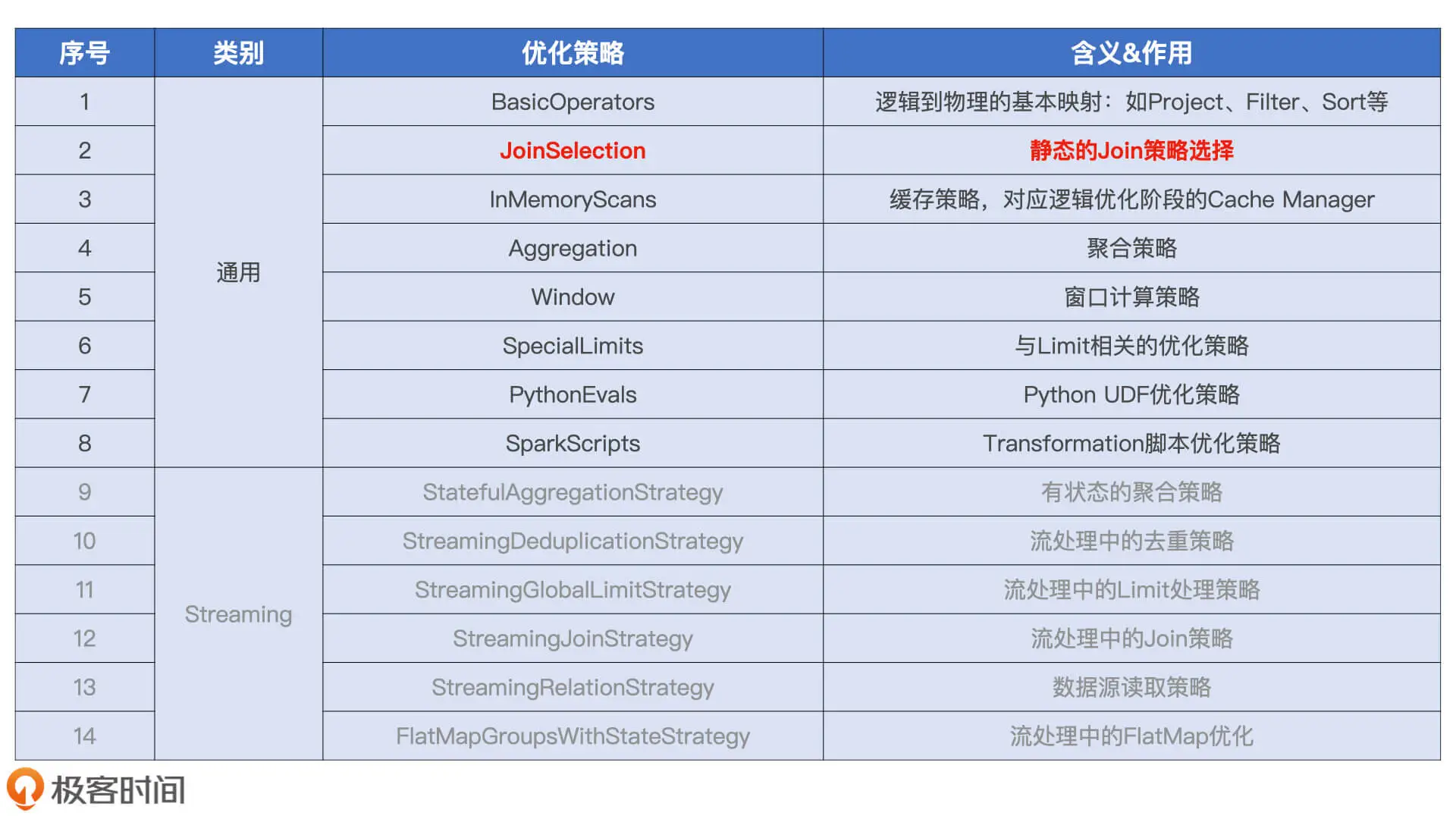
Join策略
Catalyst在运行时总共支持5种Join策略, 执行效率从高到低分别是:
- Broadcast Hash Join
- Shuffle Sort Merge Join
- Shuffle Hash Join
- Broadcast Nested Loop Join
- Shuffle Cartesian Product Join
Catalyst在选择Join策略时, 会尝试优先选择执行效率最高的策略. 也就是说, 在选择join策略时, JoinSelection会先判断当前查询是否满足BHJ所要求的先决条件, 如果满足就立即选中BHJ. 如果不满足则依次向下判断是否满足SMJ的先决条件. 依次类推, 最终使用CPJ来兜底.
JoinSelection在做决策时会依赖两类信息:
- 条件型
- Join类型
也就是我们的Join key是否是等值连接 - 内表尺寸
判断表的大小, 信息可以来自与hive表, parquet文件信息, 或者缓存大小, AQE的动态统计信息.
Spark3.x版本的AQE对此有优化
- Join类型
- 指令型
也就是Join Hints. 它允许我们主动声明想使用的Join策略, 并且在做Join策略选择时会优先选择我们的策略. 但并不是一定会选择我们的策略
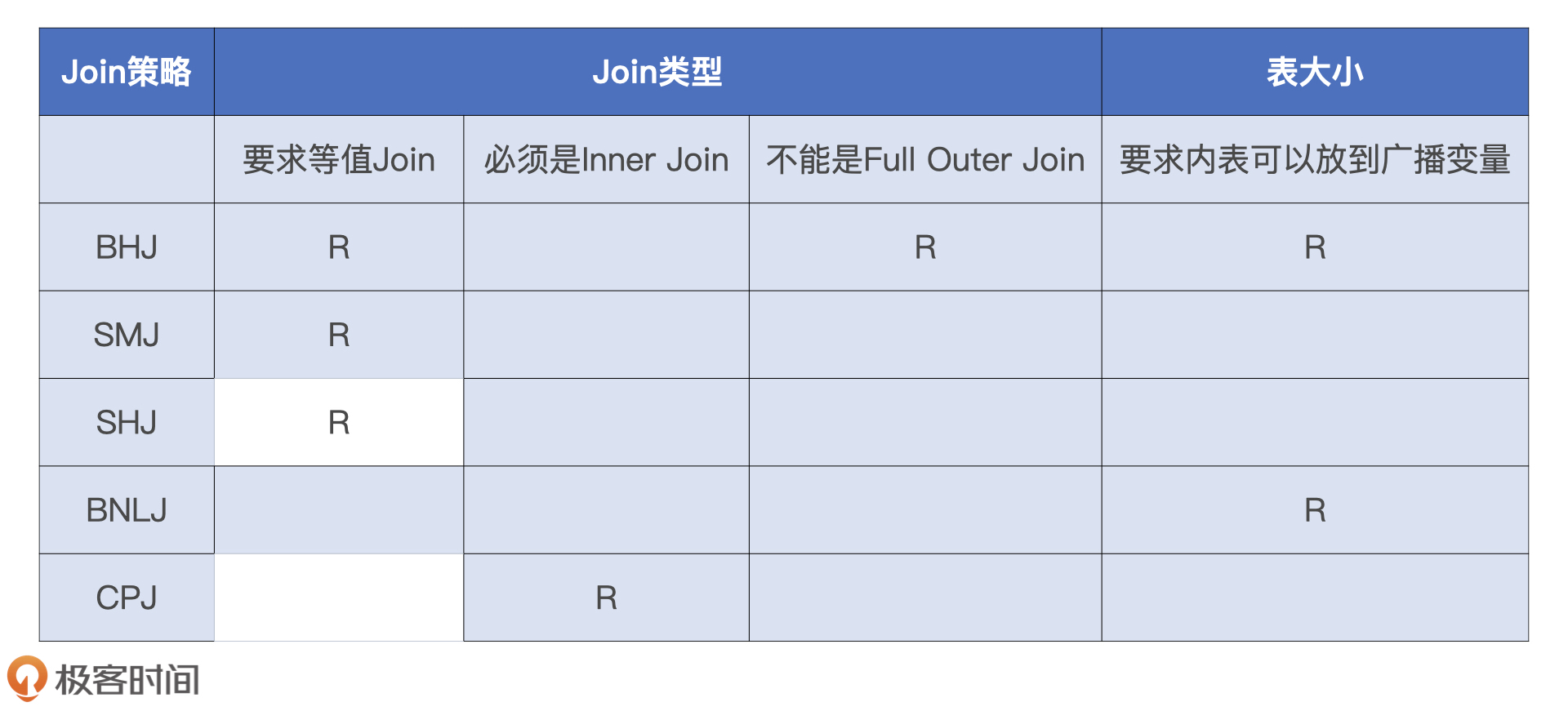
在上面的查询中, 首先选择BHJ, 但是由于右表user的尺寸太大, 所以退而求其次选择了SMJ. 这时所有条件都满足, 所以最终的Join策略为SMJ. 查询计划树如下所示: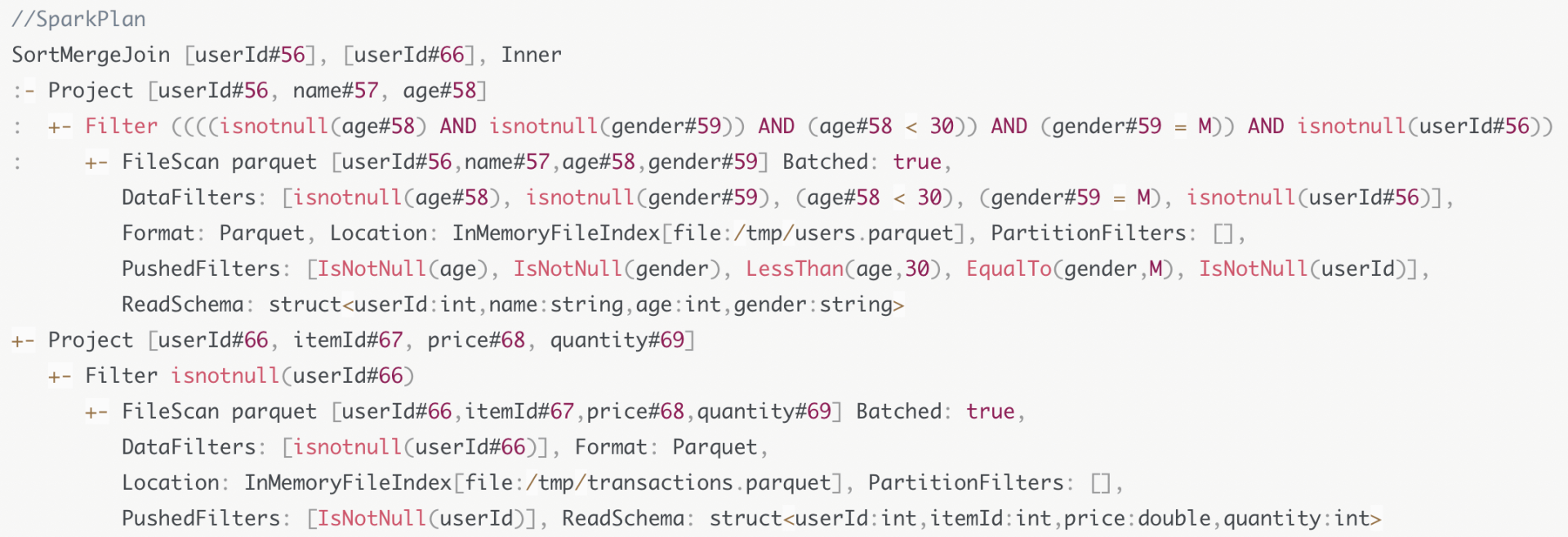
生成Physical Plan
Catalyst需要对Spark Plan做进一步的转换, 生成可以操作、可以执行的Physical Plan.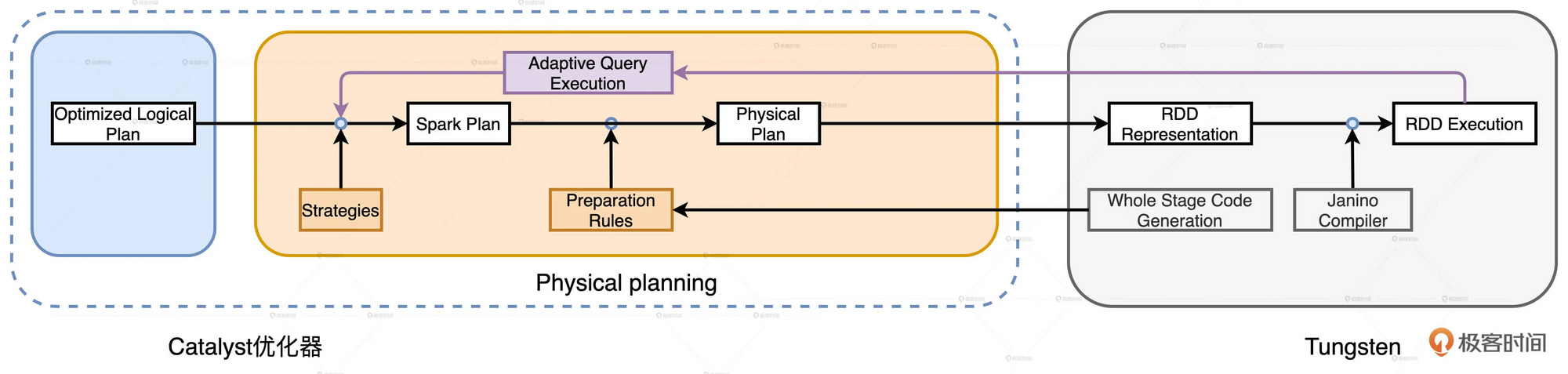
这里有一步Preparation Rules的规则, 完成这些规则后就转换成了Physical Plan.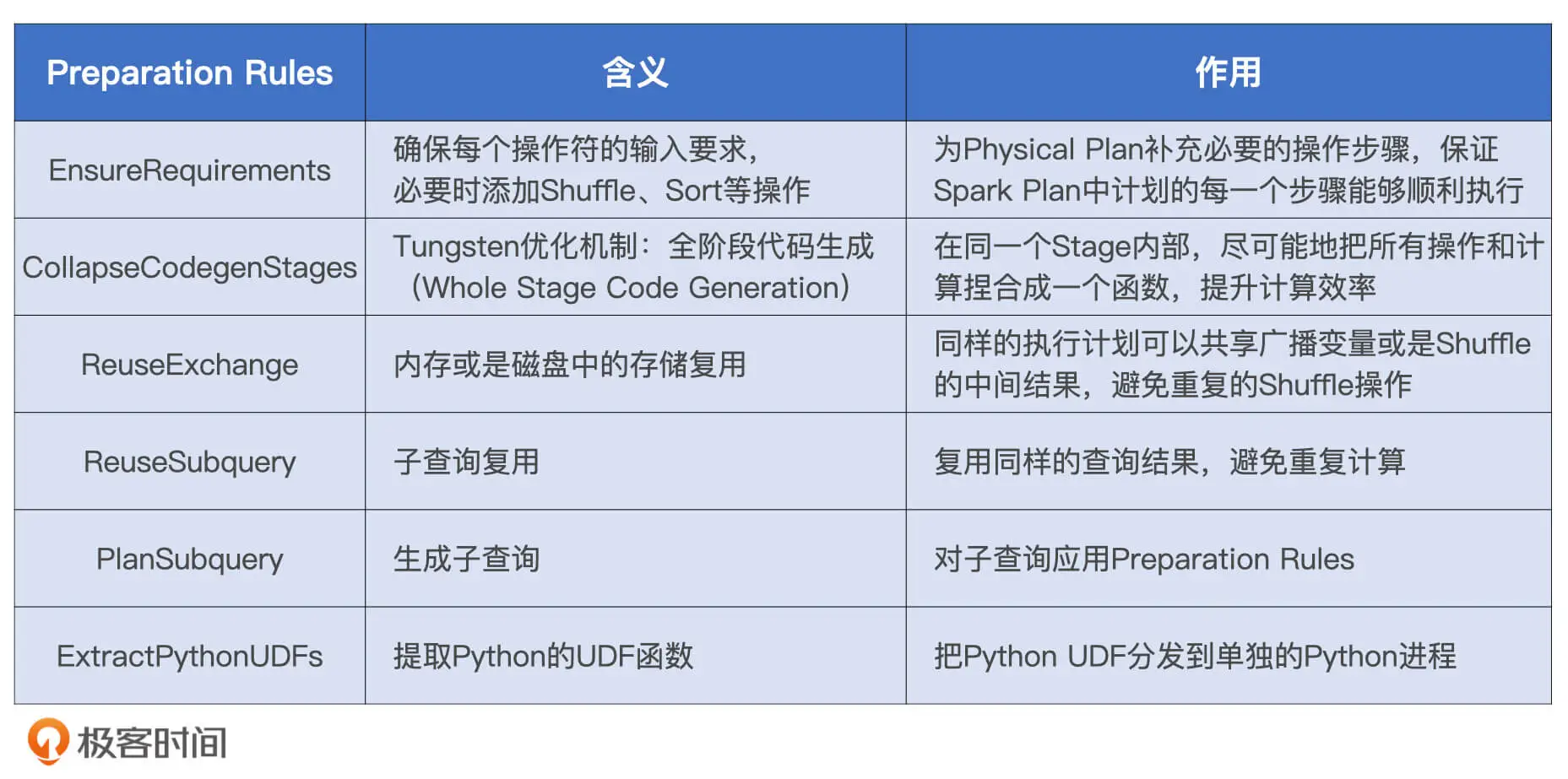
这些规则可以保证在上一步优化时添加的规则可以被执行.
例如在上面的查询中添加了Join策略为SortMergeJoin. 但是SortMergeJoin需要选择进行排序, 并且需要根据key做shuffle. 在上一步的计划中并没有声明这些信息. 那么就需要运用这些规则来完善信息.
EnsureRequirements规则
这一个规则是确保每一个节点的操作都可以满足前提条件.
每一个节点, 都会有4个属性用来描述数据输入和输出的分布状态.
- outputPartitioning 输出数据的分区规则
- outputOrdering 输出数据的排序规则
- requireChildDistribution 要求输入数据满足某种分区规则
- requireChildOrdering 要求输入数据满足某种排序规则
EnsureRequirements规则要求, 子节点的输出数据要满足父节点的输入要求.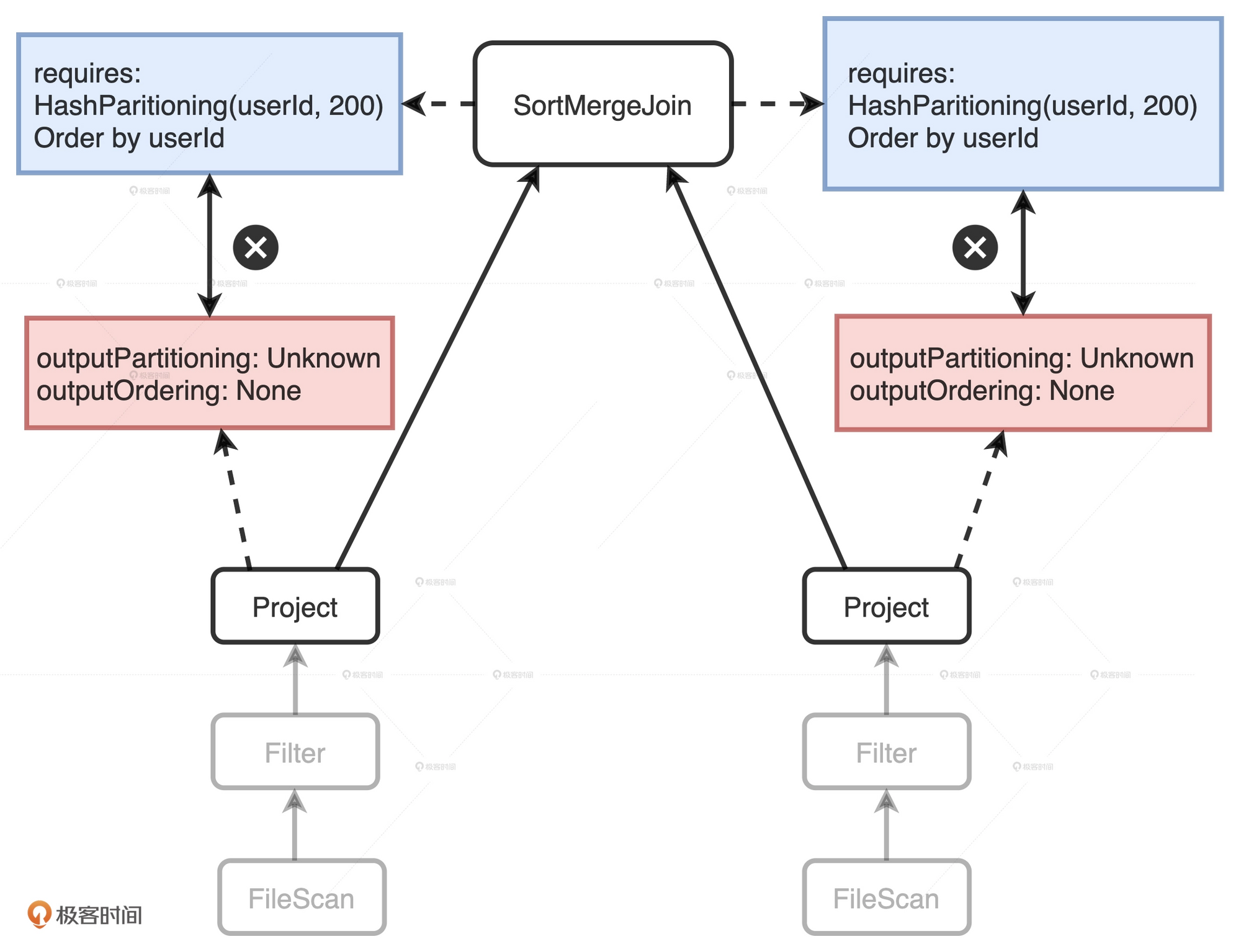
上面的图中, 父节点SortMergeJoin有两个子节点, 父节点需要两个子节点按照userId分成200个分区并且排好序. 但是在两个子节点上, 他们输出数据并没有满足这两个条件. 这时就要利用EnsureRuirements规则来将两个子节点满足父节点的输入要求. 它通过添加必要的操作符, 如Shuffle和排序, 来保证父节点SortMergeJoin节点对于输入数据的要求得到满足.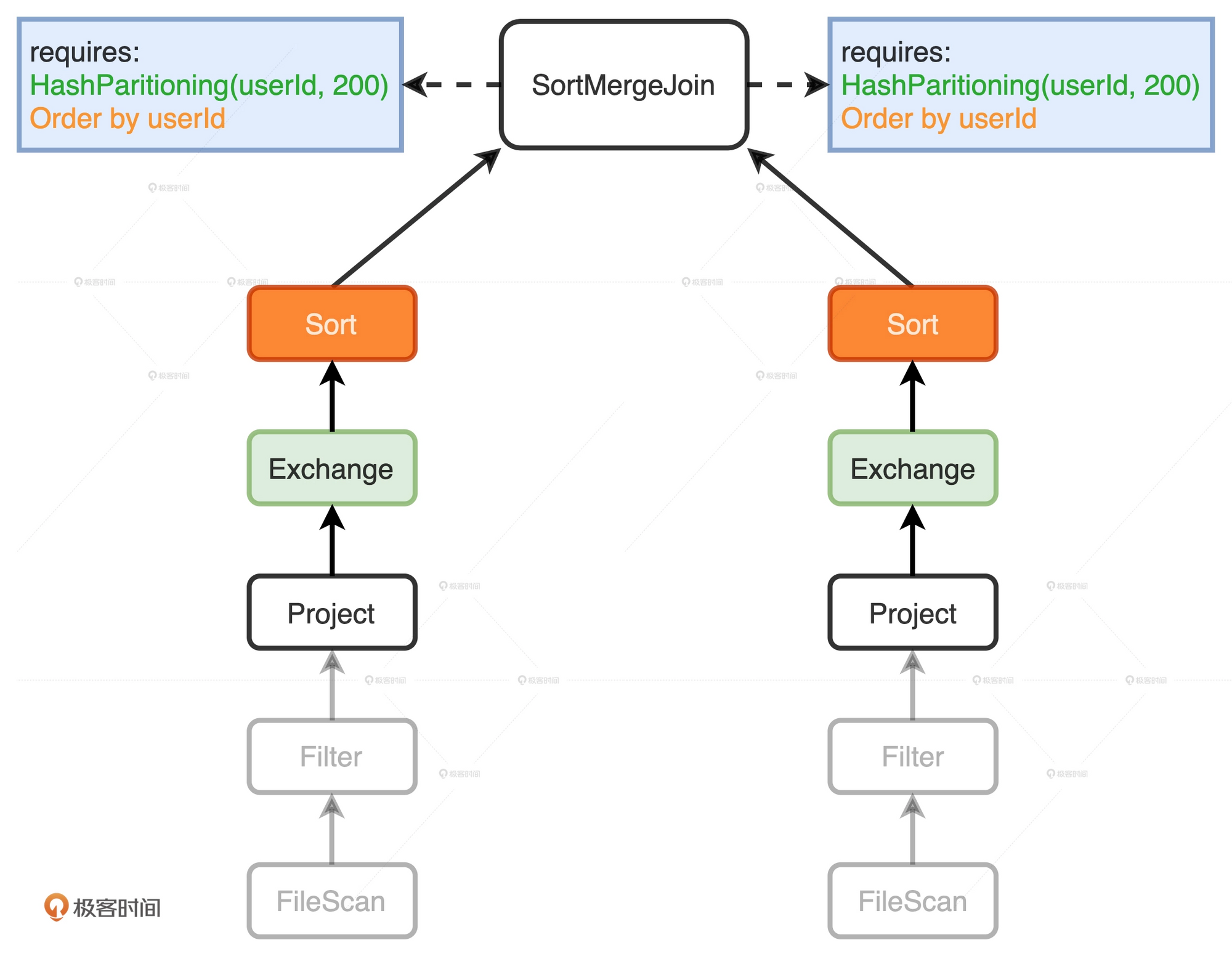
添加必需的节点之后, Physical Plan就已经相当具体, 可以去执行了.
这时spark可以调用Physical Plan的doExecute方法, 把结构化查询的计算结果, 转换为RDD[InternalRow]. 这里的InternalRow是Tungsten设计的定制化二进制数据结构.
通过调用RDD[InternalRow]之上的ACTION算子, Spark就可以触发Physical Plan从头至尾依次执行.
上面查询的Physical Plan最终如下:
Physical Plan中, 会有一些星号“”, 这些星号后面还带着括号和数字, 比如“(3)”, “*(1)”. 这种星号标记表示的就是WSCG, 后面的数字代表Stage编号. 因此, 括号中数字相同的操作, 最终都会被捏合成一份代码来执行.